
코틀린에서 data class는 정말 자주 보입니다. API 응답 모델, DTO, 상태 모델, 설정값 묶음까지 폭넓게 쓰이기 때문입니다. 하지만 많이 쓴다는 것과 정확히 이해했다는 것은 다릅니다. 이 글에서는 data class가 자동으로 무엇을 만들어 주는지, 어디서 실수하기 쉬운지, 실무에서 언제 잘 맞고 언제 더 신중해야 하는지를 쉬운 예시로 정리합니다.
먼저 핵심부터 말하면, data class의 자동 생성 기능은 주 생성자 프로퍼티만 기준으로 동작하고 copy()는 얕은 복사입니다. 이 두 가지만 제대로 이해해도 실무에서 생기는 많은 오해를 줄일 수 있습니다.
왜 코틀린에서 data class를 이렇게 자주 볼까
data class는 값을 담는 객체를 간결하게 표현하는 데 강합니다. 일반 class보다 보일러플레이트가 적고, 값 비교와 로그 출력, 일부 값만 바꾼 새 객체 생성까지 기본으로 지원합니다. 그래서 값 중심 모델을 다루는 코드에서 자주 선택됩니다.
data class User(
val id: Long,
val name: String,
val email: String
)이 선언만으로 코틀린은 equals(), hashCode(), toString(), componentN(), copy()를 자동 생성합니다. 즉, data class는 단순히 짧게 쓰는 문법이 아니라 값 중심 객체를 다루기 쉽게 만드는 도구에 가깝습니다.
data class 선언 규칙은 생각보다 중요합니다
공식 문서 기준으로 data class에는 몇 가지 중요한 제한이 있습니다. 이 제약을 모르고 쓰기 시작하면 상속이나 프레임워크 연동에서 헷갈리기 쉽습니다.
- 주 생성자에 최소 1개 이상의 파라미터가 있어야 합니다.
- 모든 주 생성자 파라미터는 val 또는 var 여야 합니다.
- data class는 abstract, open, sealed, inner 로 선언할 수 없습니다.
- 다른 클래스를 상속받을 수는 있지만, 상속 계층의 기반 타입으로 열어 두는 용도에는 적합하지 않습니다.
불가능한 선언 예시
data class Empty()
data class InvalidUser(name: String)
// data open class OpenUser(val name: String) // 불가많은 글에서 “data class는 상속이 안 된다”라고 짧게 말하지만, 더 정확한 표현은 다릅니다. data class는 상속용 기반 클래스로 열어 두기에 적합하지 않다고 이해하는 편이 안전합니다.
자동 생성되는 함수 5가지는 꼭 이해해야 합니다
data class의 진짜 핵심은 자동 생성 함수입니다. 이름만 외우지 말고, 각각이 왜 필요한지 감각적으로 이해하는 것이 중요합니다.
- equals() / hashCode(): 값이 같은 객체를 같은 것으로 비교하기 좋게 만듭니다.
- toString(): 디버깅과 로그에서 읽기 좋은 문자열을 제공합니다.
- componentN(): 구조 분해 선언을 가능하게 합니다.
- copy(): 일부 값만 바꾼 새 객체를 만들 수 있게 합니다.
값 비교 예시
data class User(val name: String, val age: Int)
fun main() {
val a = User("Lee", 20)
val b = User("Lee", 20)
println(a == b)
}copy 사용 예시
data class User(val name: String, val age: Int)
fun main() {
val user = User("Lee", 20)
val updated = user.copy(age = 21)
println(user)
println(updated)
}가장 중요한 규칙: 자동 생성은 주 생성자 프로퍼티만 기준으로 동작합니다
이 규칙을 놓치면 data class를 제대로 이해했다고 보기 어렵습니다. class body에 선언한 프로퍼티는 자동 생성되는 equals/hashCode/toString/copy/componentN 대상에서 빠질 수 있습니다.
data class Person(val name: String) {
var age: Int = 0
}
fun main() {
val person1 = Person("John")
val person2 = Person("John")
person1.age = 10
person2.age = 20
println(person1 == person2)
println(person1)
println(person2)
}즉, 같은 name을 가진 두 객체는 age가 달라도 같다고 판단될 수 있습니다. 그래서 프로퍼티를 어디에 두는지는 단순 문법 문제가 아니라 동등성 규칙 설계의 문제입니다.
이때 스스로에게 네 가지를 물어보면 도움이 됩니다. 이 값이 동등성 비교 대상인지, 복사 대상인지, 구조 분해 대상인지, 로그 출력에 포함돼야 하는지부터 정리해야 합니다.
copy()는 편하지만 깊은 복사는 아닙니다
많은 사람이 copy()를 쓰면서 가장 헷갈리는 부분이 바로 복사 범위입니다. 공식 문서 기준으로 copy()는 깊은 복사가 아니라 얕은 복사입니다.
data class Employee(
val name: String,
val roles: MutableList<String>
)
fun main() {
val original = Employee("Jamie", mutableListOf("developer"))
val duplicate = original.copy()
duplicate.roles.add("team lead")
println(original)
println(duplicate)
}이 예제에서는 duplicate.roles를 수정했는데 original.roles도 함께 바뀔 수 있습니다. 이유는 간단합니다. 겉 객체는 새로 만들었지만, 내부 리스트 참조는 공유될 수 있기 때문입니다.
data class를 쓴다고 자동으로 불변 모델이 되는 것은 아닙니다. val 중심 설계, 읽기 전용 컬렉션, 불변 객체 조합이 함께 가야 실제로 다루기 쉬운 모델이 됩니다.
구조 분해 선언은 편하지만 항상 좋은 것은 아닙니다
data class User(val name: String, val age: Int)
fun printUser(user: User) {
val (name, age) = user
println("$name / $age")
}구조 분해는 짧은 로컬 문맥에서는 읽기 좋습니다. 하지만 필드가 많아지면 순서 의존성이 커지고, 각 값의 의미를 다시 확인해야 할 수도 있습니다. 그래서 간단한 경우에만 쓰고, 의미가 복잡한 모델은 객체 이름으로 접근하는 편이 더 안전합니다.
DTO, 응답 모델, 상태 모델에는 왜 잘 맞을까
data class는 API 요청/응답 DTO, UI 모델, 상태 스냅샷, 설정값 묶음처럼 값 중심 모델에 잘 맞는 경우가 많습니다. 값 비교가 자연스럽고, 로그가 읽기 쉽고, 일부 값만 바꾼 새 객체를 만들기도 쉽기 때문입니다.
data class UserSummary(
val name: String,
val postCount: Int
)이름 없는 Pair나 Triple보다, 의미 있는 이름을 가진 data class가 대체로 더 읽기 좋습니다. 타입 이름만 봐도 이 데이터가 어떤 역할을 하는지 더 빨리 이해할 수 있기 때문입니다.
그런데 JPA Entity에는 왜 더 신중해야 할까
여기서는 강한 금지 문장보다 범위를 제한한 설명이 안전합니다. DTO처럼 가볍게 data class를 고르던 습관을 JPA Entity에 그대로 가져오면 위험할 수 있습니다. Entity는 단순 데이터 묶음이 아니라 프레임워크 규칙과 런타임 동작까지 함께 고려해야 하는 객체이기 때문입니다.
- Kotlin 클래스는 기본적으로 final 입니다.
- Kotlin은 JPA 환경을 위해 all-open, jpa, no-arg 같은 플러그인을 별도로 제공합니다.
- 자동 생성 equals/hashCode/toString이 Entity의 식별자, 변경 가능 상태, 연관관계 설계와 항상 잘 맞는 것은 아닙니다.
- 그래서 Entity는 DTO보다 더 신중하게 선택해야 합니다.
이 글에서 안전하게 말할 수 있는 결론은 이 정도입니다. DTO, 응답 모델, 상태 스냅샷에는 data class가 잘 맞는 경우가 많고, Entity는 프레임워크 제약과 동등성 설계를 함께 고려해야 하므로 더 신중한 판단이 필요합니다.
data class, 일반 class, sealed class, value class는 어떻게 구분하면 좋을까
비슷해 보이는 도구를 역할별로 나눠 보면 선택이 쉬워집니다.
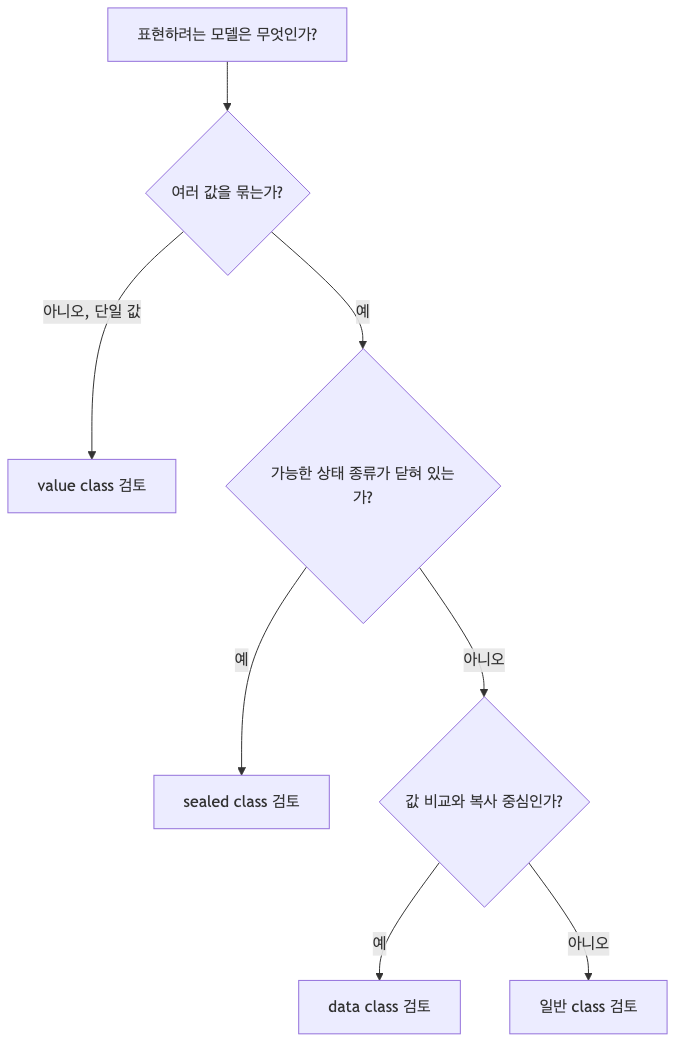
- data class: 여러 값을 묶고 값 비교와 복사가 중요한 모델
- 일반 class: 커스텀 동작, 프레임워크 제약, 직접 설계한 동등성 규칙이 중요한 모델
- sealed class: 가능한 상태 종류가 닫혀 있고 when에서 빠짐없이 처리하고 싶은 모델
- value class: 하나의 값을 더 의미 있는 도메인 타입으로 감싸고 싶은 모델
sealed class와 함께 쓰는 예시
sealed class UiState {
data object Loading : UiState()
data class Success(val data: String) : UiState()
data class Error(val message: String) : UiState()
}value class와 역할 비교
@JvmInline
value class UserId(val value: Long)sealed class는 닫힌 상태 집합을 표현할 때 강하고, value class는 단일 값을 더 의미 있는 타입으로 감쌀 때 적합합니다. 즉, data class의 상위 버전이 아니라 서로 다른 문제를 푸는 도구라고 보는 편이 맞습니다.
실무에서 바로 쓸 수 있는 판단 기준
아래 질문에 예가 많으면 data class가 잘 맞을 가능성이 큽니다.
- 이 객체는 값처럼 비교되어야 하는가?
- 일부 값만 바꾼 새 객체를 자주 만들 것인가?
- 주 생성자 프로퍼티 기준 동등성 규칙이 자연스러운가?
- DTO, 응답 모델, 상태 스냅샷에 가까운가?
- 내부를 가능한 한 불변적으로 유지할 수 있는가?
반대로 프레임워크 제약이 크거나, 자동 생성 동등성 규칙이 의도와 다를 수 있거나, 내부 가변 상태와 연관관계가 많다면 일반 class를 포함해 다른 선택지를 먼저 검토하는 편이 좋습니다.
결론: data class는 문법이 아니라 설계 도구로 봐야 합니다
정리해 보면 data class는 코틀린에서 아주 강력하고 실용적인 기능입니다. 하지만 짧아서 좋다는 이유만으로 선택하면 실무에서 오히려 헷갈릴 수 있습니다.
- 자동 생성 대상은 주 생성자 프로퍼티만입니다.
- copy()는 얕은 복사입니다.
- data class 자체가 불변성을 보장하지는 않습니다.
- DTO, 응답 모델, 상태 모델에는 잘 맞는 경우가 많습니다.
- Entity처럼 프레임워크 제약이 큰 영역에서는 더 신중해야 합니다.
- sealed class, value class, 일반 class와 역할을 구분해서 써야 합니다.
한 줄로 요약하면 이렇습니다. data class는 데이터를 예쁘게 쓰는 문법이 아니라 값 중심 모델을 읽기 좋고 안전하게 설계하기 위한 도구입니다.
 – set에 구조체 포인터 담기")

- 정렬 기준 바꾸기")
 – data class와 sealed class: 모델링을 더 명확하게 만드는 법")
 – 문자열 검색 문제에 최적화된 트라이(Trie) 자료구조(C언어, Java, Python 예시코드)")
 – 구조체 활용(set은 만능이다?)")