
Room migration이 어려운 이유를 먼저 한 줄로 말하면 이렇습니다. 개발 중인 테이블을 고치는 일이 아니라, 이미 사용자 기기에 쌓인 데이터를 안 깨뜨리고 계약을 바꾸는 일이기 때문입니다. 그래서 이 글은 SQL 문법 소개보다 production 기준의 판단법에 집중합니다.
로컬에서는 앱을 지우고 다시 깔면 끝나지만, 실제 배포 후에는 사용자마다 다른 버전 경로를 타고 올라옵니다. 어떤 사용자는 1→2, 어떤 사용자는 1→4, 어떤 사용자는 몇 달 뒤 최신 버전으로 한 번에 점프합니다. 이 차이 때문에 Room migration은 생각보다 빨리 운영 이슈가 됩니다.

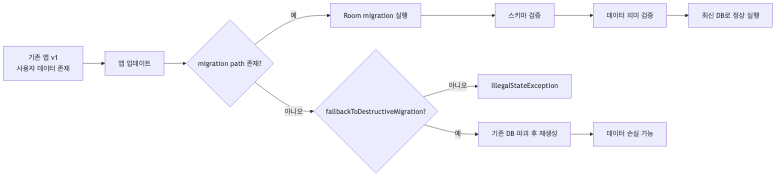
Room migration이 어려운 진짜 이유는 배포 후 데이터 때문이다
배포 후에는 이미 사용자 기기에 데이터가 들어 있고, 모든 사용자가 같은 앱 버전에 있지 않으며, 잘못된 변경은 사용자 데이터 손실이나 앱 실행 실패로 이어질 수 있습니다. 그래서 Room migration은 테이블 정의 수정이라기보다 기존 데이터를 어떻게 보존하면서 구조를 바꿀지 결정하는 작업에 가깝습니다.
- 이미 사용자 기기에 데이터가 들어 있다
- 모든 사용자가 같은 버전에 있지 않다
- 오래된 스키마에서 최신 스키마로 올라오는 경로가 여러 개다
- 잘못된 변경은 테스트 기기가 아니라 실제 사용자 기기에서 터질 수 있다
예를 들어 createdAt 컬럼 하나를 추가해도 기존 row를 어떤 값으로 채울지, 그 기본값이 정렬이나 필터 기준에서도 안전한지, 서버 동기화와 충돌하지 않는지까지 같이 봐야 합니다. 이 지점에서 migration은 단순 schema 변경이 아니라 데이터 해석 규칙 추가가 됩니다.
Room migration이 실제로 하는 일
Room은 버전이 올라갈 때 이전 스키마에서 새 스키마로 갈 수 있는 경로를 알아야 합니다. 공식 문서 기준으로 migration path가 없으면 IllegalStateException이 발생합니다. 즉 중요한 것은 version 숫자만 올리는 것이 아니라, 그 사이 차이를 어떻게 메울지 정의하고 실제 데이터에서도 안전한지 검증하는 일입니다.
val MIGRATION_1_2 = object : Migration(1, 2) {
override fun migrate(database: SupportSQLiteDatabase) {
database.execSQL(
"ALTER TABLE user ADD COLUMN createdAt INTEGER NOT NULL DEFAULT 0"
)
}
}
@Database(
entities = [UserEntity::class],
version = 2,
exportSchema = true,
)
abstract class AppDatabase : RoomDatabase() {
abstract fun userDao(): UserDao
}
val db = Room.databaseBuilder(context, AppDatabase::class.java, "app.db")
.addMigrations(MIGRATION_1_2)
.build()이 코드는 짧지만 실무 난이도는 여기서부터 시작합니다. 왜 기본값을 0으로 두는지, 그 값이 과거 데이터와 새 데이터가 섞일 때도 안전한지까지 설명할 수 있어야 진짜 migration이 됩니다.
exportSchema를 먼저 이해해야 하는 이유
Room 공식 문서는 자동 마이그레이션이 이전 버전과 새 버전의 exported schema에 의존한다고 설명합니다. 그리고 exportSchema=false 이거나 새 버전 schema가 아직 생성되지 않았다면 자동 migration이 실패할 수 있습니다. 즉 exportSchema는 장식 옵션이 아니라 migration의 기록 장치입니다.
- Room이 버전 간 차이를 계산하려면 이전 스키마 기록이 필요하다
- 테스트에서 과거 버전 DB를 재현하려면 schema history가 필요하다
- 팀이 나중에 어떤 버전에서 무엇이 바뀌었는지 추적하려면 기록이 남아 있어야 한다
schema JSON을 버전 관리에 같이 넣어 두면 migration이 깨졌을 때 원인 추적이 훨씬 쉬워집니다. 이 기록이 없으면 과거 스키마를 기억에 의존해야 하고, 그 순간부터 테스트와 복구가 모두 어려워집니다.
AutoMigration은 편하지만 만능이 아니다
Room은 기본적인 스키마 변경에 대해 자동 마이그레이션을 지원합니다. 단순한 add, 일부 rename 같은 변경에서는 코드 양을 크게 줄여 줍니다. 하지만 공식 문서도 Room이 모호한 schema change를 만나면 compile-time error를 내고 AutoMigrationSpec 구현을 요구한다고 설명합니다.
@Database(
entities = [UserEntity::class],
version = 2,
exportSchema = true,
autoMigrations = [
AutoMigration(from = 1, to = 2)
]
)
abstract class AppDatabase : RoomDatabase()대표적으로 테이블/컬럼 rename, 삭제처럼 Room이 의도를 추론하기 어려운 변경은 추가 정보가 필요합니다. 그리고 더 복잡한 데이터 분리나 의미 변경은 결국 manual migration이 더 안전한 경우가 많습니다. 자동 생성이 가능하다는 것과, 운영 데이터까지 안전하다는 것은 같은 말이 아닙니다.

AutoMigrationSpec은 왜 필요한가
rename/delete처럼 Room이 모호하게 보는 변경은 개발자가 의도를 명시해 줘야 합니다. 이때 사용하는 것이 AutoMigrationSpec입니다. 즉 “사라진 게 아니라 이름이 바뀐 것”이라는 힌트를 Room에 직접 주는 셈입니다.
@Database(
entities = [UserEntity::class],
version = 2,
exportSchema = true,
autoMigrations = [
AutoMigration(
from = 1,
to = 2,
spec = AppDatabase.RenameUserNameSpec::class,
)
]
)
abstract class AppDatabase : RoomDatabase() {
@RenameColumn(
tableName = "user",
fromColumnName = "name",
toColumnName = "displayName",
)
class RenameUserNameSpec : AutoMigrationSpec
}그래도 production에서는 질문이 남습니다. 이름만 바뀐 것인지, 의미도 바뀐 것인지, 서버나 캐시 키와의 정합성은 괜찮은지 확인해야 합니다. 또 공식 문서에는 자동 migration 뒤 추가 작업이 필요하면 onPostMigrate()를 구현할 수 있다고 나옵니다. 즉 테이블 모양만 바꿔서는 끝나지 않는 경우가 생각보다 많습니다.
결국 어려운 건 manual migration이 필요한 순간이다
Room 공식 문서도 복잡한 schema change는 manual migration이 필요할 수 있다고 분명히 말합니다. 특히 한 테이블을 둘로 나누거나, 여러 컬럼을 합쳐 새 구조로 옮기거나, 기존 텍스트를 파싱해 정규화해야 하는 경우는 개발자가 데이터 이동 규칙을 직접 책임져야 합니다.
val MIGRATION_2_3 = object : Migration(2, 3) {
override fun migrate(database: SupportSQLiteDatabase) {
database.execSQL(
"""
CREATE TABLE IF NOT EXISTS address (
userId INTEGER NOT NULL,
city TEXT,
zipCode TEXT,
detail TEXT,
PRIMARY KEY(userId)
)
""".trimIndent()
)
database.execSQL("ALTER TABLE user RENAME TO user_old")
database.execSQL(
"""
CREATE TABLE IF NOT EXISTS user (
id INTEGER NOT NULL,
name TEXT NOT NULL,
PRIMARY KEY(id)
)
""".trimIndent()
)
database.execSQL("INSERT INTO user (id, name) SELECT id, name FROM user_old")
database.execSQL("INSERT INTO address (userId, detail) SELECT id, addressText FROM user_old")
database.execSQL("DROP TABLE user_old")
}
}이쯤 오면 Room migration이 어려운 이유가 분명해집니다. SQL이 어렵다기보다 옛 데이터를 새 의미로 옮기는 규칙을 개발자가 책임져야 한다는 점이 어렵습니다.
왜 production에서는 더 어렵게 느껴질까
1. 사용자는 항상 최신 직전 버전에서만 올라오지 않는다
개발자는 흔히 1→2만 테스트하고 안심합니다. 하지만 실제 사용자는 1→4, 2→5, 3→5처럼 여러 경로로 올라옵니다. 그래서 최신 코드에서 새 DB를 처음 만드는 것과, 오래된 DB가 여러 migration을 거쳐 최신 구조가 되는 것은 전혀 다른 문제입니다.
2. 스키마 변경보다 데이터 의미 변경이 더 위험하다
name에서 displayName으로 바뀌는 건 기술적으로는 rename 같아 보여도, 예전 name이 로그인 ID였고 새 displayName이 노출 이름이라면 그냥 rename만으로는 의미가 깨집니다. migration이 코드 작업이 아니라 정책 작업이 되는 순간입니다.
3. fallbackToDestructiveMigration은 편의와 운영 안정성을 혼동하게 만든다
공식 문서 기준으로 migration path가 없을 때 fallbackToDestructiveMigration()을 쓰면 Room은 DB를 파괴적으로 재생성합니다. 개발 중에는 편하지만 운영 데이터가 있는 앱에서는 오프라인 메모, 임시 저장, 서버 동기화 전 데이터가 모두 사라질 수 있습니다. 그래서 이 옵션은 에러를 없애는 버튼이 아니라 데이터 손실을 감수하겠다는 선언으로 봐야 합니다.
4. SQLite 자체 제한도 같이 이해해야 한다
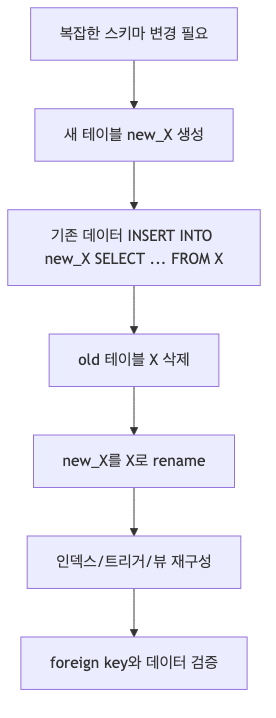
SQLite 공식 문서는 ALTER TABLE 지원이 제한적이라고 분명히 말합니다. 기본적으로 rename table, rename column, add column, drop column 정도만 직접 지원합니다. 더 복잡한 변경은 새 테이블 생성, 데이터 복사, 기존 테이블 삭제, 이름 변경, 인덱스/트리거/뷰 재구성을 거쳐야 할 수 있습니다. 즉 Room migration이 어려운 건 Room만의 문제가 아니라 아래쪽 저장소 엔진의 제약까지 함께 다뤄야 하기 때문입니다.
실전 예시 3개로 보는 Room migration 판단법
예시 1. 컬럼 추가는 쉬워 보여도 기본값 정책이 중요하다
isPinned 같은 컬럼 추가는 SQL 한 줄로 끝날 수 있습니다. 하지만 기존 row를 정말 모두 false로 봐도 되는지, 서버 동기화와 충돌은 없는지, 예전 즐겨찾기 기능이 다른 테이블에 숨어 있지는 않은지까지 같이 봐야 합니다. 쉬운 migration도 기본값 정책을 잘못 잡으면 나중에 더 큰 버그가 됩니다.
예시 2. 컬럼 이름 변경은 기술보다 의미 호환성이 중요하다
rename 가능 여부보다 먼저, 예전 데이터가 새 의미에서도 그대로 유효한지를 봐야 합니다. 단순 UI 표기용 이름 변경이면 rename으로 충분할 수 있지만, 로그인 식별자에서 노출 이름으로 의미가 바뀌는 경우라면 별도 컬럼 추가와 데이터 변환이 더 안전할 수 있습니다.
예시 3. 테이블 분리는 사실상 데이터 마이그레이션 프로젝트에 가깝다
기존 NoteEntity에 태그 문자열을 콤마로 저장하다가 TagEntity와 CrossRef 구조로 바꾸는 순간, migration은 문자열 파싱, 중복 제거, 빈 값 처리, cross ref 생성까지 포함한 데이터 정제 작업이 됩니다. 이때는 AutoMigration보다 manual migration과 검증 코드가 훨씬 중요해집니다.
MigrationTestHelper는 왜 꼭 봐야 할까
Room은 room-testing 아티팩트와 MigrationTestHelper를 제공합니다. 이 helper는 exported schema를 읽고 migration 테스트를 도와줍니다. 핵심은 migration이 실제로 실행되는지, 실행 후 스키마가 기대한 구조와 일치하는지 빠르게 검증하는 데 있습니다.
@RunWith(AndroidJUnit4::class)
class MigrationTest {
@get:Rule
val helper = MigrationTestHelper(
InstrumentationRegistry.getInstrumentation(),
AppDatabase::class.java,
)
@Test
fun migrate1To2() {
helper.createDatabase("test-db", 1).apply {
execSQL("INSERT INTO user (id, name) VALUES (1, Alice)")
close()
}
helper.runMigrationsAndValidate(
"test-db",
2,
true,
MIGRATION_1_2,
)
}
}중요한 점은 schema validation만으로는 부족하다는 것입니다. 공식 문서 취지도 결국 “스키마는 검증되지만, 데이터가 기대대로 옮겨졌는지는 직접 확인해야 한다”에 가깝습니다. 그래서 테스트에서는 기본값, null 처리, 데이터 복사 결과, foreign key 무결성, 실제 조회 결과까지 함께 확인해야 합니다.

단일 migration 테스트보다 전체 경로 테스트가 중요한 이유
1→2가 통과했다고 해서 1→2→3→4가 안전하다는 뜻은 아닙니다. 오래된 schema JSON, manual SQL, rename 규칙이 조금만 어긋나도 처음부터 최신 DB를 만든 경우와 오랜 경로를 거쳐 올라온 경우의 최종 상태가 달라질 수 있습니다. 그래서 Room 공식 문서도 전체 migration 경로를 포함한 테스트를 권장합니다.
Room migration 체크리스트
- 이 변경은 구조만 바뀌는가, 데이터 의미도 바뀌는가
- 기존 row를 어떤 값으로 채울지 명확한가
- AutoMigration으로 충분한가, AutoMigrationSpec이 필요한가, manual migration이 더 안전한가
- schema export가 버전 관리에 남아 있는가
- 단일 migration 테스트뿐 아니라 전체 경로 테스트가 있는가
- fallbackToDestructiveMigration을 켜도 되는 데이터인가
- foreign key, index, trigger, 실제 조회 결과가 바뀌지 않는가
이 체크리스트에서 하나라도 애매하면, Room migration은 쉬운 작업이 아니라는 신호입니다.
언제 AutoMigration을 쓰고 언제 manual migration으로 가야 할까
- 의미 변화가 거의 없는 단순 스키마 변경 → AutoMigration 우선 검토
- rename/delete처럼 Room이 모호하게 보는 변경 → AutoMigrationSpec 검토
- 데이터 재해석, 테이블 분리/병합, 파싱/보정 필요 → manual migration이 더 안전
- 자동 생성 가능 여부와 운영 데이터 안전성을 분리해서 판단
중요한 건 자동이 더 최신이어서 무조건 좋다가 아니라, 운영 데이터에 맞는 수준의 통제력을 선택하는 것입니다.
관련 글과 함께 보면 더 이해가 쉬운 흐름
Room Flow는 왜 편할까는 저장소가 바뀐 뒤 UI가 어떻게 다시 읽히는지 보는 관점이고, 안드로이드 Repository 패턴은 어디까지 필요할까는 DB 접근을 어디까지 감싸야 migration 영향이 덜 퍼지는지 보는 관점입니다. 또 안드로이드 SavedStateHandle은 언제 필요할까, rememberSaveable과 SavedStateHandle 차이는 화면 상태와 영속 데이터 경계를 어떻게 나눌지 다시 보게 해 줍니다.
특히 Room migration을 자주 힘들게 만드는 팀은 DB 스키마 자체보다 상태 저장 경계와 데이터 책임 분리가 불분명한 경우가 많습니다. 그래서 Room/DB 글과 상태 관리 글을 같이 묶어 읽는 편이 실제 설계 감각을 더 빨리 키워 줍니다.
migration을 더 안전하게 만드는 작은 습관
실무에서는 migration 코드를 쓰는 것보다, schema JSON을 꾸준히 커밋하고 테스트 DB를 오래된 버전에서 직접 올려 보는 습관이 더 큰 차이를 만듭니다. 작은 습관이 production 장애를 줄입니다.
또 migration을 한 번에 크게 몰아 하기보다, 의미가 분명한 작은 단계로 나누면 테스트와 롤백 판단이 훨씬 쉬워집니다.
마무리
정리하겠습니다. Room migration이 어려운 이유는 SQL이 복잡해서가 아닙니다. 이미 존재하는 사용자 데이터를 잃지 않고, 여러 버전 경로를 거쳐, 새 구조와 새 의미로 안전하게 옮겨야 하기 때문입니다.
그래서 migration에서 진짜 중요한 것은 schema export를 남기는 것, 자동과 수동의 경계를 구분하는 것, destructive fallback을 편의 기능으로 착각하지 않는 것, 그리고 전체 migration 경로와 데이터 무결성을 테스트하는 것입니다.
공식 문서는 Migrate Room databases, SQLite ALTER TABLE, SQLite Foreign Key Support를 함께 보면 좋습니다.





