
좌표 압축은 코딩테스트를 하다 보면 꽤 자주 만나지만, 처음에는 왜 굳이 값을 다시 바꾸는지 감이 잘 안 잡히는 개념입니다. 값이 10, 100, 1000000처럼 크더라도 그냥 그대로 쓰면 되는 것 아닌가 싶기 때문입니다.
이번 글에서는 좌표 압축을 어려운 기법처럼 소개하지 않고, 값 자체보다 상대적인 순서와 위치만 중요할 때 다시 번호를 매기는 방법으로 설명하겠습니다.

좌표 압축이 필요한 상황은 어떤 모습일까
예를 들어 값의 범위가 1부터 10억까지 가능한데, 실제 입력에 등장하는 값은 8개뿐이라고 해보겠습니다. 이때 값 범위 전체를 배열 인덱스로 잡으면 메모리가 너무 비효율적입니다.
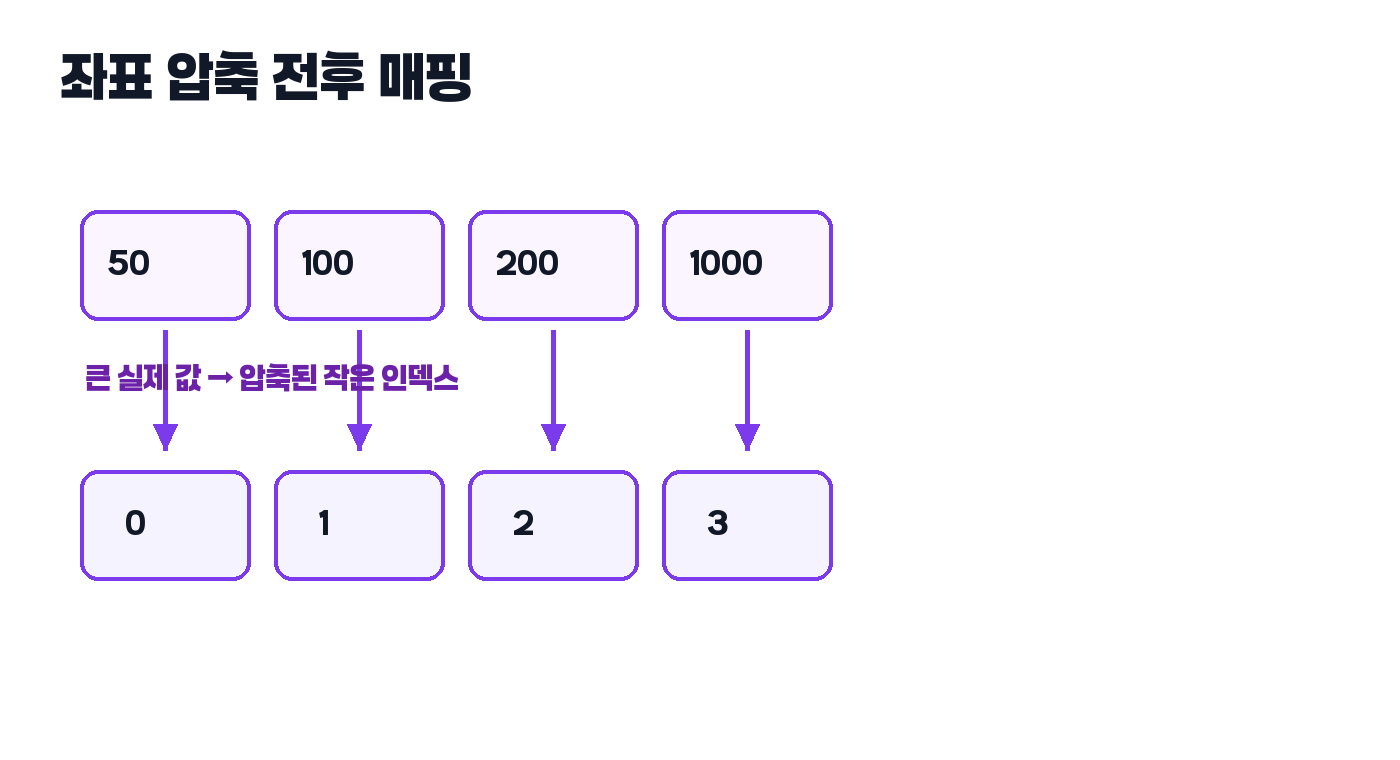
하지만 실제로 필요한 것은 “이 값이 몇 번째로 작은가” 또는 “이 값보다 작은 값이 몇 개 있는가” 같은 상대적 정보인 경우가 많습니다. 이때 등장한 값들만 모아서 0, 1, 2, 3처럼 다시 번호를 붙이면 훨씬 다루기 쉬워집니다.
핵심은 값의 크기가 아니라 순서를 보존하는 것이다
좌표 압축은 값을 아무렇게나 줄이는 것이 아닙니다. 중요한 것은 대소 관계를 유지하는 것입니다. 원래 a < b였다면 압축한 뒤에도 a의 번호 < b의 번호가 되도록 만들어야 합니다.
즉 좌표 압축은 값의 실제 의미를 버리는 대신, 알고리즘이 필요로 하는 순서 정보만 남기는 과정이라고 볼 수 있습니다.
보통 어떻게 만들까
values = [100, 50, 1000, 50, 200]
unique = sorted(set(values))
compressed = {v: i for i, v in enumerate(unique)}
result = [compressed[v] for v in values]
# unique = [50, 100, 200, 1000]
# result = [1, 0, 3, 0, 2]과정은 보통 세 단계입니다. 첫째, 등장한 값만 뽑아 중복을 제거합니다. 둘째, 정렬해서 순서를 잡습니다. 셋째, 정렬된 순서대로 새 인덱스를 매깁니다.
이렇게 하면 원래 값이 얼마나 컸는지는 사라지지만, 상대 순서는 그대로 남습니다. 대부분의 자료구조 문제에서 필요한 것은 바로 이 순서 정보입니다.
여기서 헷갈리기 쉬운 부분은 “압축된 값이 원래 값의 크기를 뜻하는가?”입니다. 아닙니다. 압축된 값은 단지 순서를 보존한 새 인덱스일 뿐입니다. 그래서 1000이 3으로 압축됐다고 해서 값이 3처럼 작아졌다는 의미가 아니라, 네 번째로 큰 값이라는 뜻에 가깝습니다.
왜 코딩테스트에서 특히 중요할까

좌표 압축을 처음 배울 때 가장 많이 나오는 질문은 “결국 값이 줄어드는 건 알겠는데, 왜 그게 정답을 망치지 않지?”입니다. 답은 단순합니다. 이 문제들에서는 실제 값보다 상대적인 순서 정보만 필요하기 때문입니다.
세그먼트 트리, 펜윅 트리, 빈도 배열, 누적 카운트처럼 인덱스를 써야 하는 자료구조는 범위가 너무 크면 바로 다루기 어렵습니다. 이때 좌표 압축을 해두면 거대한 값을 작은 연속 구간으로 바꿔서 자료구조에 올릴 수 있습니다.
이 감각은 누적합 글처럼 범위를 효율적으로 다루는 사고와도 닿아 있고, 더 나아가 펜윅 트리나 세그먼트 트리 같은 인덱스 기반 구조의 준비 단계로 자주 등장합니다. 참고 개념으로는 세그먼트 트리 자료도 연결해볼 수 있습니다.
즉 좌표 압축은 독립 알고리즘이라기보다, 다른 자료구조를 현실적으로 쓰기 위한 전처리 역할을 자주 합니다.
언제 쓰면 안 될까
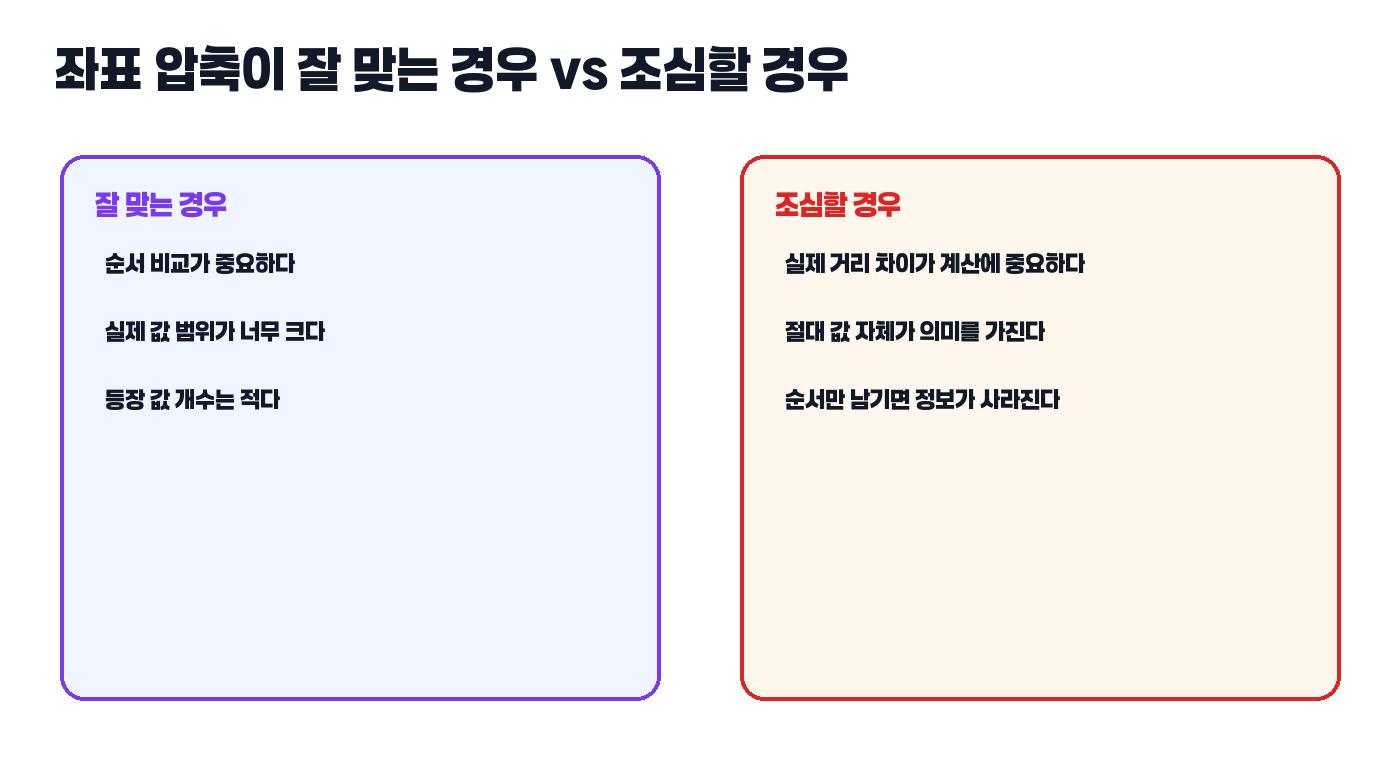
값의 실제 차이가 중요한 문제에서는 좌표 압축을 조심해야 합니다. 예를 들어 좌표 간의 실제 거리 자체가 계산에 들어간다면, 순서만 보존해서는 정보가 부족할 수 있습니다.
즉 좌표 압축은 “값이 얼마인가”보다 “값이 몇 번째인가”가 중요할 때만 잘 맞습니다.
문제에서 어떤 신호가 보이면 떠올릴까
- 값 범위가 매우 크다
- 하지만 실제 등장하는 값의 개수는 적다
- 순서 비교나 인덱스 매핑이 중요하다
- 세그먼트 트리나 펜윅 트리를 쓰고 싶은데 범위가 너무 크다
이 신호가 보이면 좌표 압축을 먼저 의심하는 편이 좋습니다. 특히 값 범위가 10억 단위인데 입력 개수는 2만, 5만 정도인 문제는 대표적인 후보입니다.
자주 하는 실수
- 정렬은 했는데 중복 제거를 빼먹는다
- 원래 값과 압축 값의 관계를 헷갈린다
- 실제 거리까지 필요한 문제에 순서 정보만 남긴다
- 압축 후 인덱스 시작점을 문제 구현과 맞추지 못한다
특히 중복 처리와 실제 거리 보존 여부를 잘못 판단하면 오답이 자주 납니다.
즉 좌표 압축은 만능 전처리가 아닙니다. 순서를 남기는 대신 실제 거리 정보를 버리는 선택이기 때문에, 문제에서 무엇이 중요한지 먼저 판단해야 합니다. 이 구분까지 해야 비로소 좌표 압축을 제대로 이해한 것입니다.
마무리
좌표 압축의 핵심은 큰 값을 마법처럼 줄이는 것이 아니라, 알고리즘에 필요한 순서 정보만 남기고 나머지는 버리는 데 있습니다.
즉 값 범위는 큰데 실제 값 개수는 적고, 순서만 중요할 때 좌표 압축은 매우 자연스러운 선택이 됩니다.





