
코틀린 Interpreter 패턴은 디자인 패턴 책에서 이름은 자주 보이지만, 실제 코드에서는 어디까지 적용해야 하는지 감이 잘 안 오는 패턴입니다. 이유는 이 패턴이 단순 클래스 하나를 감싸는 구조가 아니라, 작은 언어 규칙이나 표현식을 객체 구조로 바꾸어 해석하는 흐름과 연결되기 때문입니다.
이번 글에서는 Interpreter 패턴을 추상 정의로 끝내지 않고, 간단한 규칙 언어를 AST처럼 표현하고 evaluate 흐름으로 해석하는 구조로 설명하겠습니다. 그리고 코틀린에서는 어디서 더 읽기 쉬워지고, 어디서부터는 오히려 과해지는지도 같이 보겠습니다.

왜 이 패턴이 필요한가
코드 안에 작은 규칙 언어가 숨어 있는 경우가 있습니다. 예를 들어 조건식을 문자열로 저장했다가 평가하거나, 필터 규칙을 조합하거나, 검색 쿼리를 객체로 풀어내야 하는 상황입니다. 이때 if문과 분기 로직이 커질수록 규칙 구조가 코드 속에 흩어져 버립니다.
Interpreter 패턴은 이 문제를 “규칙을 객체 구조로 표현하고, 각 객체가 자기 의미를 해석하게 한다”는 방향으로 풀려고 합니다. 그래서 핵심은 실행 자체보다 문법과 해석 책임을 구조로 드러내는 것입니다.
가장 짧은 정의: 문법 규칙을 클래스 구조로 옮긴다
Interpreter 패턴은 표현식의 문법 요소를 클래스 계층으로 나누고, 각 노드가 evaluate 같은 메서드로 자신의 의미를 계산하게 만드는 패턴입니다. 즉 Number, Plus, Minus, Variable 같은 요소가 각자 객체가 됩니다.
이 구조는 작은 언어를 트리로 본다고 이해하면 쉽습니다. 하나의 큰 수식이 있고, 그 안에 하위 표현식이 있고, 각 표현식이 다시 자신의 하위 표현식을 갖습니다. 결국 전체 문장은 트리 구조가 됩니다.
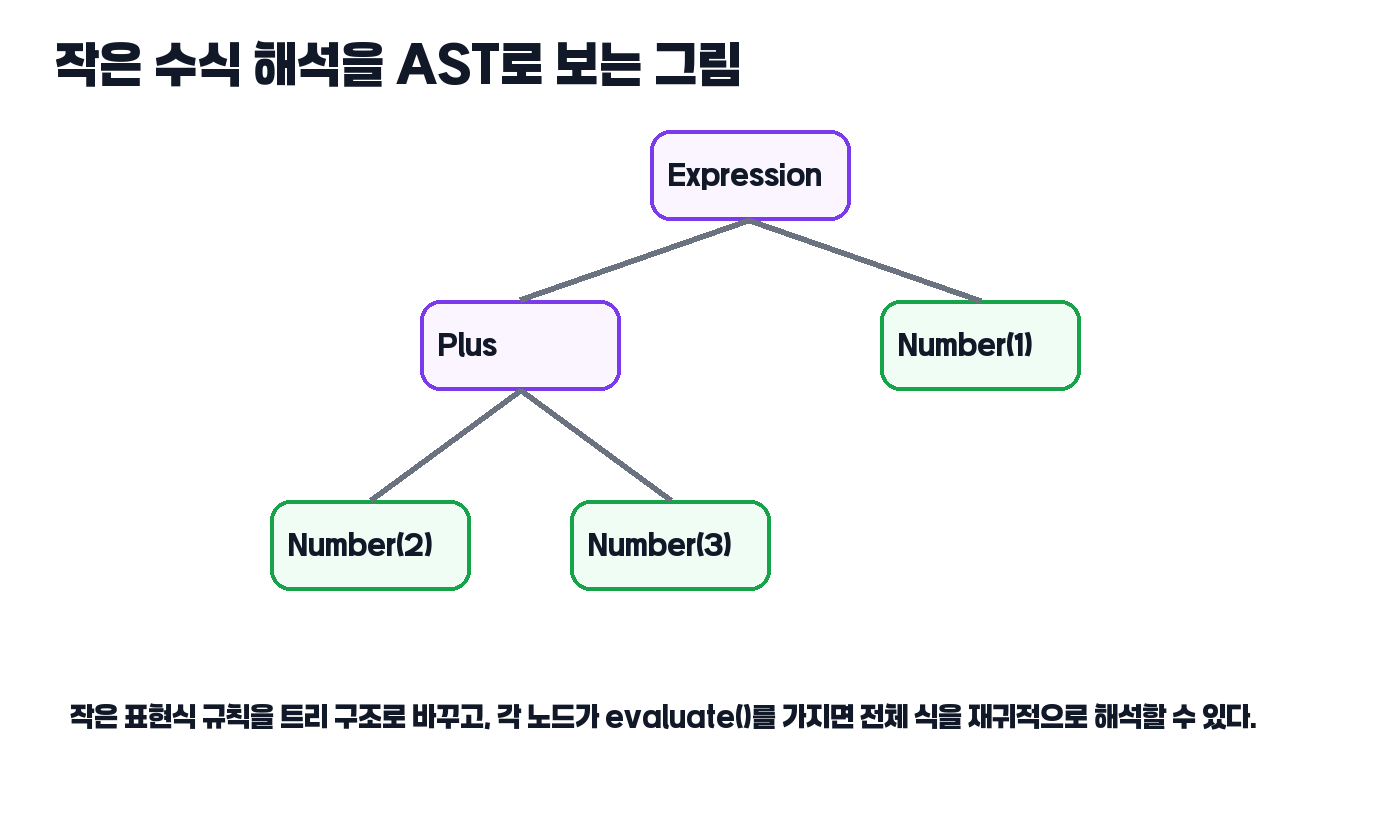
입문자가 많이 헷갈리는 부분은 여기서 parser와 interpreter를 한 덩어리로 보는 것입니다. 하지만 개념상은 구분하는 편이 좋습니다. parser는 입력을 구조로 바꾸고, interpreter는 그 구조의 의미를 계산합니다. 작은 예제에서는 두 단계가 섞여 보일 수 있지만, 머릿속에서는 분리해 두는 편이 훨씬 이해가 쉽습니다.
코틀린 코드로 보면 어떻게 생길까
sealed interface Expr {
fun evaluate(): Int
}
data class NumberExpr(private val value: Int) : Expr {
override fun evaluate(): Int = value
}
data class PlusExpr(
private val left: Expr,
private val right: Expr,
) : Expr {
override fun evaluate(): Int = left.evaluate() + right.evaluate()
}
data class MinusExpr(
private val left: Expr,
private val right: Expr,
) : Expr {
override fun evaluate(): Int = left.evaluate() - right.evaluate()
}
val expr: Expr = PlusExpr(
NumberExpr(1),
MinusExpr(NumberExpr(5), NumberExpr(2))
)
println(expr.evaluate()) // 4이 예제의 핵심은 evaluate가 한곳에 몰려 있지 않다는 점입니다. NumberExpr는 자기 값을 반환하고, PlusExpr는 왼쪽과 오른쪽을 평가한 뒤 더하고, MinusExpr는 뺍니다. 즉 각 표현식 객체가 자기 의미를 스스로 계산합니다.
코틀린에서는 sealed interface와 data class를 쓰면 이 구조가 꽤 읽기 좋게 정리됩니다. 전통적인 자바 스타일로 구현하면 상속 계층과 보일러플레이트가 더 무거워질 수 있는데, 코틀린은 작은 AST를 표현할 때 그 무게를 줄여줍니다.
동작 흐름은 어떻게 읽어야 할까
실행 시점에는 보통 전체 표현식의 루트 노드에서 evaluate를 호출합니다. 그러면 루트는 하위 노드 평가를 요청하고, 하위 노드는 자기 하위 노드를 다시 평가합니다. 이렇게 재귀적으로 내려갔다가, 숫자 같은 terminal expression에서 실제 값을 반환하면서 다시 올라옵니다.
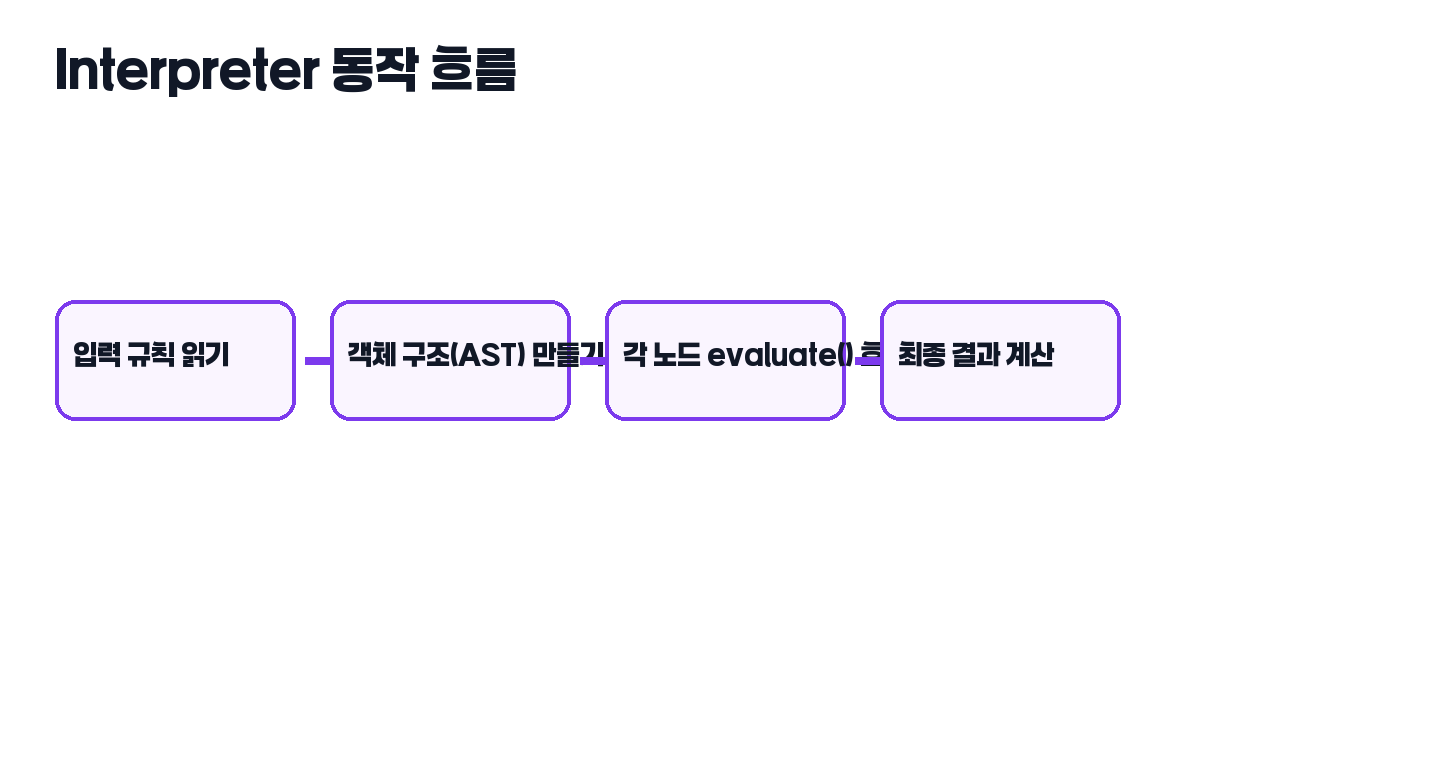
즉 Interpreter 패턴은 결국 트리를 따라 내려가며 의미를 계산하는 구조입니다. 그래서 트리, 재귀, AST, 평가기(evaluator)라는 단어들이 자주 함께 나옵니다.
어떤 문제에서 자연스러울까
- 간단한 수식 계산기나 조건식 평가기
- 검색 필터 DSL처럼 규칙을 조합하는 구조
- 정책 규칙을 객체화해서 테스트 가능하게 만들고 싶을 때
- 문법 요소가 작고 비교적 안정적일 때
핵심은 문법이 작고, 규칙 요소를 객체 단위로 나누었을 때 읽기 좋아지는 문제여야 한다는 점입니다. 예를 들어 수식, 조건식, 간단한 쿼리 규칙은 Interpreter 패턴과 잘 맞습니다.
언제는 오히려 과할까
문법이 커지기 시작하면 클래스 수가 빠르게 늘어납니다. terminal/non-terminal expression이 많아지고 parser 단계까지 복잡해지면, 패턴이 주는 깔끔함보다 유지보수 부담이 더 커질 수 있습니다.
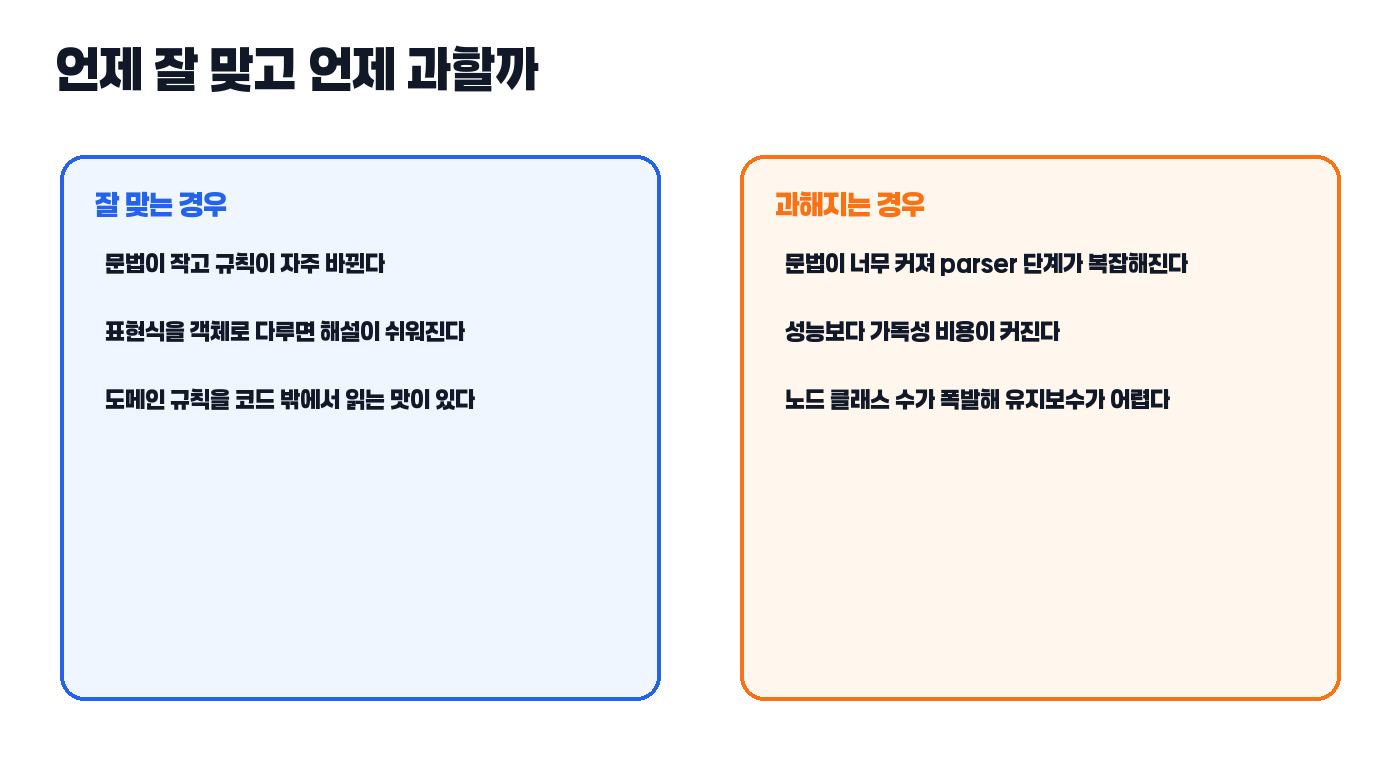
즉 Interpreter 패턴은 “언어를 만들 수 있다”는 가능성보다 “작은 규칙을 구조적으로 드러내는 데 적합하다”는 쪽으로 이해하는 편이 안전합니다. 진짜 문법이 커지면 parser generator나 전용 쿼리 엔진, rule engine 쪽을 보는 편이 낫습니다.
코틀린다운 포인트는 무엇일까
고전적인 Interpreter 패턴 설명은 Refactoring.Guru의 Interpreter 패턴 정리를 참고할 수 있고, 코틀린의 표현식 계층은 Kotlin sealed classes 공식 문서와도 자연스럽게 연결됩니다.
코틀린에서는 sealed class/ sealed interface 덕분에 표현식 계층을 닫힌 집합처럼 다루기 쉽습니다. data class는 각 노드의 필드를 드러내기 좋고, when과 함께 쓰면 디버깅이나 별도 evaluator 구현도 읽기 쉬워집니다.
다만 이것이 Interpreter 패턴을 완전히 대체한다는 뜻은 아닙니다. 코틀린 문법은 구조 표현을 단순하게 해줄 뿐이고, 여전히 중요한 것은 규칙을 객체 구조로 나눌 가치가 있는지입니다.
sealed class 감각은 이후 State, Visitor 같은 후반 패턴과도 이어지고, 실행 단위 구조는 Command 패턴 글, 조건 분해 구조는 Chain of Responsibility 글과도 비교해 볼 수 있습니다.
헷갈리는 포인트
- parser와 interpreter는 같은 말이 아니다
- 작은 DSL에는 잘 맞지만 큰 문법 시스템에는 금방 무거워질 수 있다
- 노드 클래스를 많이 만드는 것이 목적이 아니라 규칙 책임을 분리하는 것이 목적이다
- 단순한 if문 몇 개면 충분한 문제에 억지로 적용하면 과설계가 된다
특히 마지막이 중요합니다. 디자인 패턴은 “쓸 수 있다”와 “써야 한다”가 다릅니다. Interpreter 패턴은 적용하면 멋있어 보일 수 있지만, 문법이 너무 작다면 오히려 함수 몇 개가 더 읽기 쉬울 수도 있습니다.
마무리
코틀린 디자인 패턴 15편의 핵심은 이렇습니다. Interpreter 패턴은 작은 규칙 언어나 표현식을 객체 구조로 만들고, 각 노드가 자기 의미를 해석하게 만드는 패턴입니다.
그래서 이 패턴은 단순한 계산 로직을 예쁘게 감싸는 데 쓰기보다, 규칙을 구조로 드러내고 해석 책임을 분리해야 하는 상황에서 특히 의미가 큽니다. 반대로 문법이 너무 커지거나 규칙이 너무 단순하다면 다른 도구나 더 단순한 구조가 나을 수 있습니다.
코틀린 디자인 패턴 시리즈
코틀린 디자인 패턴 시리즈(0) – 왜 아직도 디자인 패턴을 배워야 할까
코틀린 디자인 패턴(1) – Singleton 패턴은 언제 쓰고 object는 어떻게 다를까
코틀린 디자인 패턴(2) – Factory Method 패턴으로 생성 책임 나누기
코틀린 디자인 패턴(3) – Abstract Factory 패턴은 언제 필요할까
코틀린 디자인 패턴(4) – Builder 패턴과 named argument는 어떻게 다를까
코틀린 디자인 패턴(5) – Prototype 패턴과 data class copy 정리
코틀린 디자인 패턴(6) – Adapter 패턴으로 기존 코드를 새 인터페이스에 맞추기
코틀린 디자인 패턴(7) – Bridge 패턴은 상속 폭발을 어떻게 줄일까
코틀린 디자인 패턴(8) – Composite 패턴으로 트리 구조 다루기
코틀린 디자인 패턴(9) – Decorator 패턴은 상속 대신 어떻게 확장할까
코틀린 디자인 패턴(10) – Facade 패턴으로 복잡한 시스템 감추기
코틀린 디자인 패턴(11) – Flyweight 패턴은 메모리를 어떻게 아낄까
코틀린 디자인 패턴(12) – Proxy 패턴은 Decorator와 무엇이 다를까

: 생성과 연결 분리하기")
 – Proxy 패턴은 Decorator와 무엇이 다를까")
: 큰 인터페이스가 왜 문제이고 언제 나눠야 할까")

