
다익스트라 알고리즘은 코딩테스트에서 자주 나오지만, 많은 입문자가 BFS를 배운 뒤에 “최단거리면 그냥 BFS 아닌가?”에서 한 번 막힙니다. 실제로 어떤 문제는 BFS로 충분하고, 어떤 문제는 BFS로는 틀립니다. 이 경계를 제대로 이해해야 다익스트라가 갑자기 외워야 할 알고리즘이 아니라 자연스러운 확장처럼 보입니다.
이번 글에서는 다익스트라를 공식을 먼저 외우는 방식이 아니라, 가중치가 붙는 순간 왜 BFS 사고방식이 깨지는지부터 설명하겠습니다. 그리고 그 자리를 우선순위 큐가 어떻게 메우는지도 단계적으로 보겠습니다.

BFS는 왜 최단거리 문제에 강할까
BFS는 간선의 비용이 모두 같을 때 강합니다. 한 칸 이동, 한 번 변환, 한 단계 확장처럼 매번 비용이 동일하다면 먼저 방문한 경로가 곧 가장 짧은 경로가 됩니다. 그래서 queue에 넣는 순서가 곧 거리 순서가 됩니다.
즉 BFS는 “먼저 도착한 것이 가장 짧다”는 가정이 자연스럽게 성립하는 문제에서 잘 맞습니다. 격자 최단거리나 레벨 탐색 문제에서 BFS가 강한 이유가 여기에 있습니다.
이 감각은 BFS 문제 풀이 패턴 글과 직접 연결됩니다.
가중치가 붙는 순간 BFS는 왜 흔들릴까
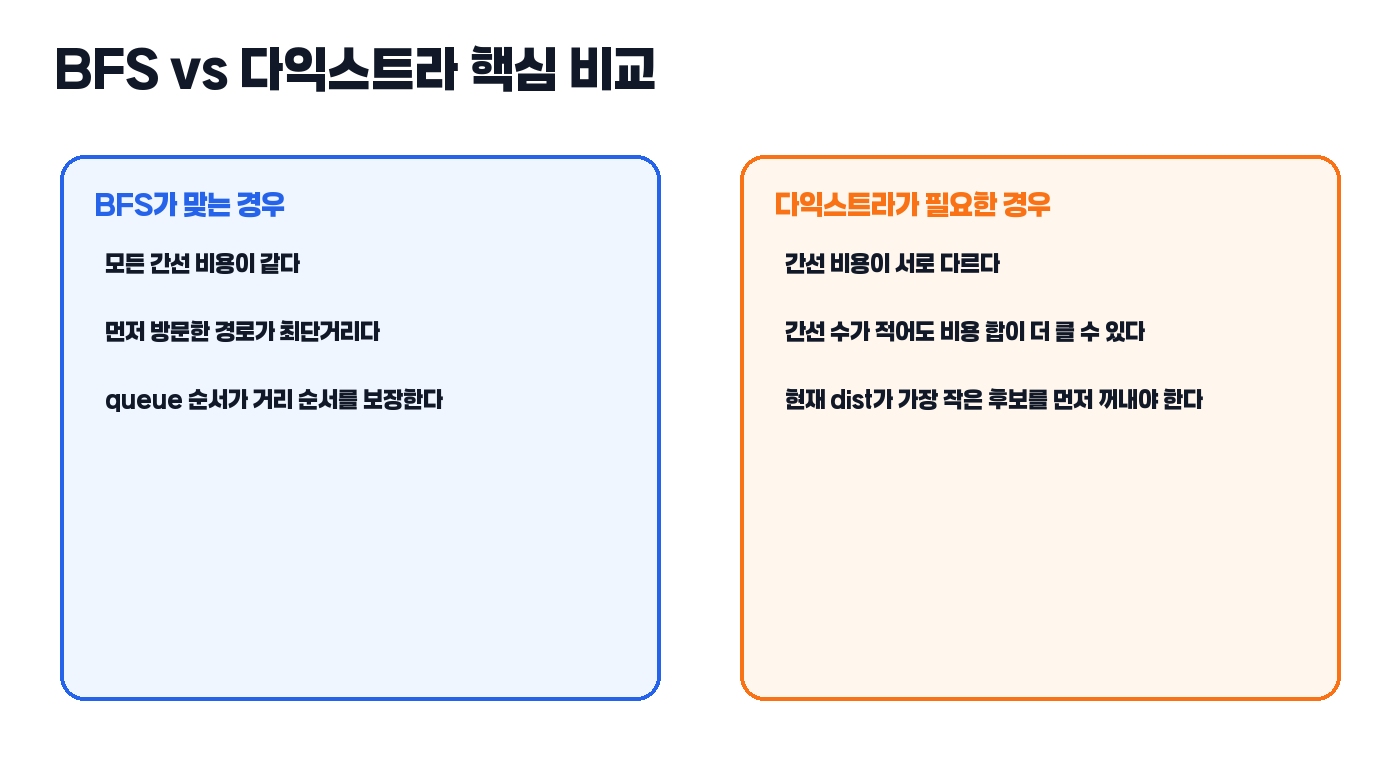
입문자 관점에서 제일 중요한 차이는, BFS는 간선 수가 곧 비용이라는 가정 위에서만 안전하다는 점입니다. 반면 다익스트라는 간선 수보다 누적 비용을 직접 비교해야 하므로, “누가 먼저 queue에 들어왔는가”보다 “누가 지금 더 싼가”가 더 중요합니다.
문제는 이동 비용이 모두 같지 않을 때입니다. 예를 들어 어떤 간선은 비용 1이고, 어떤 간선은 비용 5라면 먼저 방문했다고 해서 더 짧은 경로라고 보장할 수 없습니다. queue는 입력된 순서를 보장할 뿐, 현재까지의 최소 비용 순서를 보장하지 않기 때문입니다.
즉 BFS는 “방문 순서 = 최단거리 순서”라는 전제가 필요합니다. 가중치가 생기면 그 전제가 무너지므로, 더 이상 단순 queue만으로는 현재 가장 유리한 후보를 먼저 꺼낼 수 없습니다.
입문자가 여기서 가장 많이 헷갈리는 부분은 “그래도 먼저 간 길이 더 빨리 도착한 것 아닌가?”입니다. 하지만 가중치가 다르면 간선 개수가 적다고 해서 총 비용이 작은 것이 아닙니다. 즉 BFS는 간선 수를 잘 세지만, 비용 합은 잘 세지 못합니다.
다익스트라는 무엇을 대신 보장할까
다익스트라는 queue 순서 대신, 현재까지 알려진 거리(dist)가 가장 작은 정점부터 처리한다는 원칙을 세웁니다. 그래서 단순 FIFO가 아니라 우선순위 큐가 필요합니다.
즉 다익스트라의 핵심은 그래프를 특별하게 순회하는 것이 아니라, “지금 가장 가까운 후보부터 확정한다”는 규칙을 끝까지 지키는 데 있습니다.
priority_queue 참고처럼 우선순위를 기준으로 가장 중요한 원소를 먼저 꺼내는 구조가 여기서 직접 연결됩니다.
import heapq
def dijkstra(start, graph, n):
INF = 10**15
dist = [INF] * n
dist[start] = 0
pq = [(0, start)]
while pq:
cur_dist, cur = heapq.heappop(pq)
if cur_dist > dist[cur]:
continue
for nxt, weight in graph[cur]:
nd = cur_dist + weight
if nd < dist[nxt]:
dist[nxt] = nd
heapq.heappush(pq, (nd, nxt))
return dist위 코드에서 if cur_dist > dist[cur]: continue 조건도 중요합니다. 우선순위 큐에는 같은 정점이 여러 번 들어갈 수 있기 때문에, 이미 더 짧은 경로가 확정된 오래된 후보는 건너뛰어야 합니다. 이 부분을 모르면 코드가 왜 중복 후보를 허용하는지 이해가 잘 안 됩니다.
또 하나 자주 헷갈리는 점은 방문 배열 처리입니다. BFS처럼 처음 꺼냈다고 바로 “완전 방문”으로 생각하기보다, 현재 후보 거리가 최신인지 dist 배열과 비교하는 습관이 더 중요합니다.
이 코드에서 중요한 줄은 두 군데입니다. 하나는 heap에서 가장 작은 거리 후보를 꺼내는 부분이고, 다른 하나는 더 짧은 경로를 찾았을 때만 dist를 갱신하는 부분입니다. 즉 다익스트라는 방문 여부 자체보다 “현재까지의 최단거리 추정값”을 관리하는 알고리즘에 더 가깝습니다.
우선순위 큐가 왜 꼭 필요한가
만약 단순 queue를 쓰면 먼저 들어온 후보가 먼저 나옵니다. 하지만 다익스트라는 지금까지의 거리 값이 더 작은 후보를 먼저 처리해야 합니다. 이 요구를 가장 자연스럽게 만족하는 자료구조가 우선순위 큐입니다.
즉 다익스트라는 그래프 알고리즘이면서 동시에 우선순위 큐 문제이기도 합니다. 이 점에서 힙 글과도 강하게 이어집니다.
문제에서 어떤 신호가 보이면 다익스트라일까
- 최단거리인데 간선 비용이 모두 같지 않다
- 한 시작점에서 여러 정점까지 최소 비용을 구해야 한다
- 그래프나 격자에서 이동 비용이 칸마다 다르다
- 현재 가장 유리한 후보를 계속 먼저 확정해야 한다
이 네 가지 중 두세 가지가 같이 보이면 다익스트라 가능성이 큽니다. 반대로 비용이 모두 같다면 굳이 다익스트라까지 갈 필요 없이 BFS가 더 단순하고 적절한 경우가 많습니다.
자주 하는 실수
- 가중치가 있는데도 BFS처럼 방문 배열만 보고 끝낸다
- 우선순위 큐를 쓰면서도 더 짧은 경로 갱신 조건을 잘못 둔다
- 음수 가중치 문제에 다익스트라를 억지로 적용한다
- visited를 너무 일찍 확정해서 더 좋은 경로를 놓친다
특히 음수 가중치 문제는 다익스트라의 전제와 맞지 않습니다. 이 경우는 다른 알고리즘 축을 봐야 합니다. 즉 다익스트라는 강력하지만, 아무 최단거리 문제에나 만능은 아닙니다.
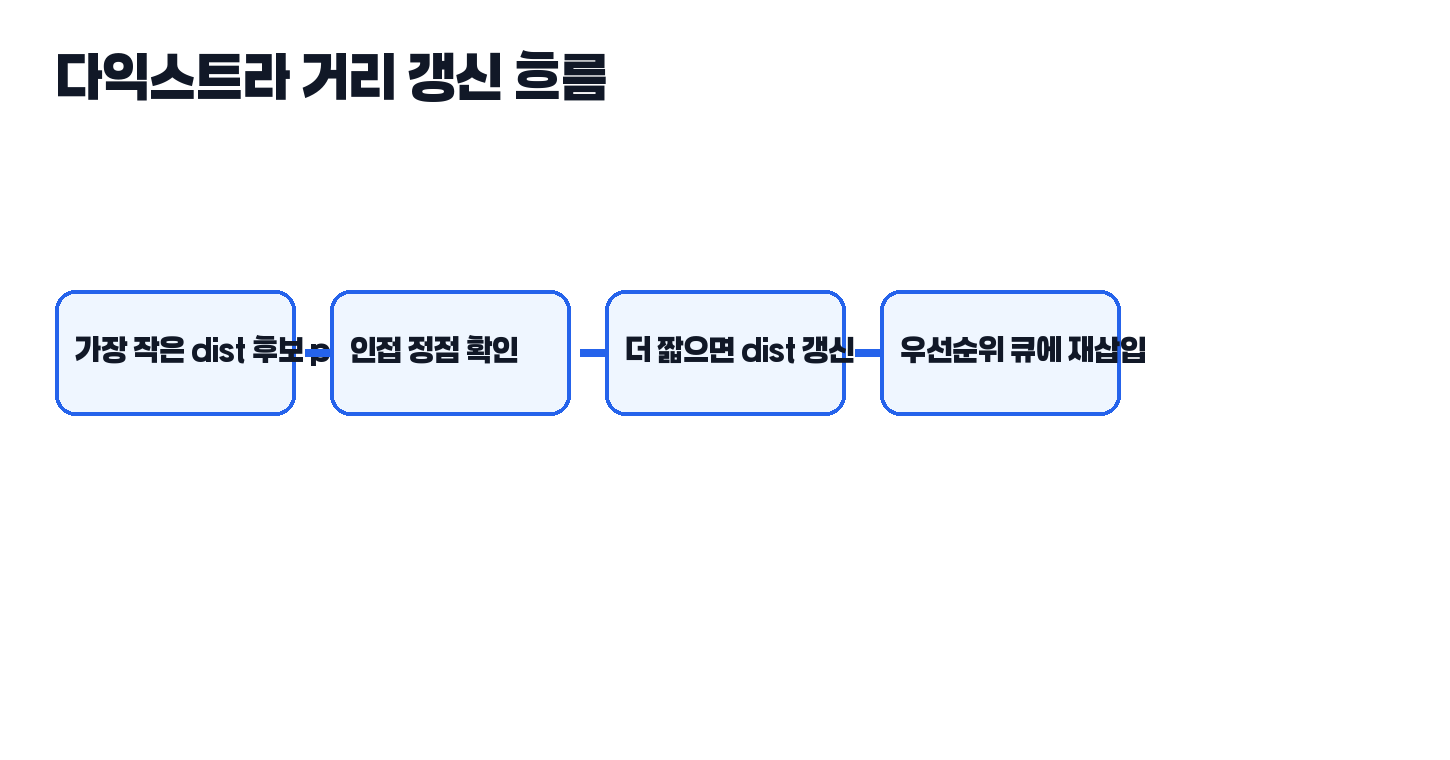

이 추적 그림을 한 번 눈으로 따라가 보면, 다익스트라는 정점을 한 번씩만 방문하는 단순 탐색이 아니라 “현재까지의 최단거리 가설”을 계속 더 나은 값으로 수정해 가는 과정이라는 점이 더 분명해집니다.
마무리
다익스트라를 이해하는 핵심은 공식을 외우는 것이 아니라, 왜 BFS가 더 이상 거리 순서를 보장하지 못하는지 먼저 보는 데 있습니다.
즉 가중치가 붙으면 queue가 아니라 현재 거리 기준 우선순위가 필요하다는 점만 잡혀도, 다익스트라는 훨씬 덜 낯설어집니다.





 자료구조 (C언어, Java, Python 예시코드)")