
Jetpack Compose 성능 이야기를 시작하면 금방 이런 말이 나옵니다. ‘recomposition이 너무 많이 돈다’, ‘Compose는 리스트가 느리다’, ‘remember를 더 붙여야 한다’ 같은 말입니다.
그런데 실무에서는 이 순서로 접근하면 오히려 헛손질이 많습니다. Compose에서 recomposition은 원래 일어나야 하는 정상 동작이기 때문입니다. 그래서 먼저 물어야 할 질문은 ‘왜 다시 그려졌지?’가 아니라 ‘어디까지 다시 계산됐고, 원래 건너뛸 수 있었던 부분이 왜 skip되지 못했지?’에 가깝습니다.
Compose 성능은 recomposition의 존재보다 recomposition의 범위, 비용, skip 가능성에서 갈리는 경우가 많습니다.
오해부터 풀자
많은 분이 recomposition을 화면 전체가 매번 새로 만들어지는 일처럼 받아들입니다. 하지만 Compose에서 recomposition은 상태가 바뀌었을 때 필요한 composable을 다시 읽는 과정에 가깝습니다. 즉, recomposition 자체는 버그도 아니고 최적화 실패의 증거도 아닙니다.
- 작은 상태 변화인데 너무 넓은 범위가 같이 다시 계산될 때
- 원래 skip될 수 있었던 부분이 계속 같이 실행될 때
- composable 안에서 비싼 정렬, 필터링, 문자열 가공을 매번 다시 할 때
- 리스트 재정렬이나 상태 이동이 key 없이 일어나서 항목 상태가 흔들릴 때
즉, Compose가 느릴 때 정말 봐야 하는 것은 recomposition이 있느냐 없느냐가 아니라 왜 이 범위가 다시 돌았고, 그 비용이 왜 커졌는가입니다.
recomposition부터 봐야 하는 이유
recomposition을 이해하지 못하면 stability도, key도, remember도 다 흩어진 팁처럼 보입니다. 하지만 실제로는 하나의 질문으로 연결됩니다. 상태가 바뀌면 어디가 다시 읽히는지, 그중 무엇은 skip될 수 있는지, skip되지 못했다면 이유가 무엇인지, 그리고 다시 읽힌 범위 안에서 비싼 계산이 숨어 있지는 않은지를 보는 흐름입니다.
이 흐름을 모르면 성능 튜닝이 금방 주술처럼 변합니다. remember를 붙이고, derivedStateOf를 붙이고, @Immutable까지 붙여도 왜 빨라졌는지 모르거나 아무 변화가 없는 경우가 생깁니다.
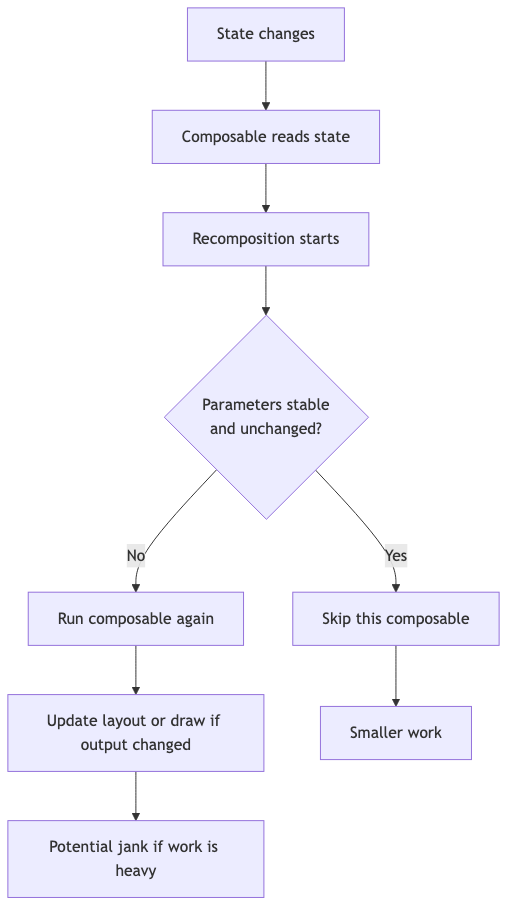
상태 변경이 발생하면 recomposition은 시작될 수 있습니다. 하지만 모든 composable이 끝까지 다시 실행되는 것은 아닙니다. 파라미터가 stable하고 값이 바뀌지 않았다면 Compose는 해당 composable을 건너뛸 수 있습니다. 즉, recomposition을 줄인다는 말보다 skip 가능한 구조를 만든다는 말이 더 정확할 때가 많습니다.
stability
Compose 공식 문서는 타입을 stable 또는 unstable로 봅니다. 아주 단순하게 말하면, 이 값이 바뀌었는지 Compose가 믿고 판단할 수 있으면 skip 판단이 쉬워지고, 그렇지 않으면 더 보수적으로 움직이게 됩니다.
- data class라고 해서 자동으로 다 해결되는 것은 아니다
- 내부 프로퍼티가 mutable하거나 Compose가 변화를 신뢰하기 어려운 타입이면 unstable로 취급될 수 있다
- 특히 컬렉션은 기본적으로 그냥 넘기면 skip 판단이 까다로워질 수 있다
data class FeedUiState(
val items: List<FeedItem>,
val selectedIds: Set<Long>
)
data class FeedItem(
val id: Long,
var title: String,
var isLiked: Boolean
)문제는 var가 있다는 사실 하나만이 아닙니다. 리스트 자체도, 내부 아이템도, 어떤 경로로 값이 바뀌는지 Compose가 보수적으로 볼 여지가 커집니다. 실무에서는 UI에 넘기는 모델을 가능한 한 읽기 전용에 가깝게 유지하는 쪽이 훨씬 안전합니다.
@Immutable
data class FeedItemUiModel(
val id: Long,
val title: String,
val isLiked: Boolean
)물론 unstable 파라미터가 있다고 무조건 느려지는 것은 아닙니다. 다만 리스트가 크고 상태 변화가 잦은 화면이라면 stability는 실제 체감 성능과 꽤 자주 연결됩니다.
key
리스트 화면에서 가장 실무적인 함정은 key입니다. Compose lazy list는 기본적으로 항목 위치를 기준으로 상태를 보려 합니다. 이 말은 순서가 바뀌거나 항목이 중간에 삽입되면, 아이템이 가진 remembered state가 원래 항목을 따라가지 못할 수 있다는 뜻입니다.
LazyColumn {
items(items = books) { book ->
BookRow(book = book)
}
}정렬이나 삽입이 일어나면 항목 상태와 위치가 어긋나기 쉽습니다. 펼쳐 둔 카드가 다른 항목으로 옮겨 붙거나, rememberSaveable 값이 예상과 다른 row에 남는 식입니다. 이럴 때는 stable하고 unique한 key를 명시하는 것이 먼저입니다.
LazyColumn {
items(
items = books,
key = { it.id }
) { book ->
BookRow(book = book)
}
}key는 항목 상태를 데이터와 함께 움직이게 만드는 기준점입니다. 특히 row 안에서 remember나 rememberSaveable을 쓰는 화면이라면 key를 빼고 성능을 이야기하면 절반은 놓치게 됩니다.
리스트에서 자주 느려지는 곳
Compose 리스트가 느리게 느껴질 때 실제로는 recomposition보다 리스트 안에서 매번 다시 하는 일이 더 큰 경우가 많습니다. 대표적인 예가 composable 안에서 정렬이나 필터링을 바로 수행하는 패턴입니다.
@Composable
fun ContactList(
contacts: List<Contact>,
comparator: Comparator<Contact>
) {
LazyColumn {
items(contacts.sortedWith(comparator)) { contact ->
ContactRow(contact)
}
}
}겉보기에는 짧고 깔끔하지만, sortedWith()가 composable 안에서 계속 호출되면 상태 변화가 있을 때마다 정렬 비용이 다시 들어갈 수 있습니다. 공식 best practices 문서도 이런 계산은 remember로 캐시하거나 더 위쪽 계층에서 미리 만들어 내려보내는 쪽을 권장합니다.
@Composable
fun ContactList(
contacts: List<Contact>,
comparator: Comparator<Contact>
) {
val sortedContacts = remember(contacts, comparator) {
contacts.sortedWith(comparator)
}
LazyColumn {
items(
items = sortedContacts,
key = { it.id }
) { contact ->
ContactRow(contact)
}
}
}여기서 중요한 포인트는 ‘remember를 쓰면 무조건 빨라진다’가 아닙니다. 중요한 것은 비싼 계산이 recomposition 범위 안에 들어와 있느냐입니다. 이미 ViewModel에서 안정적으로 준비된 결과가 내려오고 있다면, 여기서 또 remember를 붙일 이유가 없을 수도 있습니다.
derivedStateOf
derivedStateOf도 비슷합니다. 유명한 최적화 도구이지만 아무 데나 붙인다고 이득이 생기지는 않습니다. 예를 들어 스크롤 위치에 따라 ‘맨 위로’ 버튼만 토글하고 싶다면, 스크롤 값 전체를 넓은 범위에서 직접 읽는 것보다 파생된 Boolean만 노출하는 편이 좋을 수 있습니다.
val listState = rememberLazyListState()
val showScrollTop by remember {
derivedStateOf { listState.firstVisibleItemIndex > 0 }
}이 패턴이 의미 있는 이유는 스크롤 값의 세세한 변화 전체가 아니라 버튼 표시 여부라는 더 작은 상태만 하위 UI에 전달하기 때문입니다. 반대로 단순한 계산인데도 습관처럼 derivedStateOf를 남발하면 읽기 비용만 늘고 실익은 거의 없을 수 있습니다.
측정부터 하자
Compose 성능 글에서 가장 위험한 문장은 ‘이렇게 바꾸면 빨라진다’입니다. 공식 codelab도 성능 문제를 볼 때 measure, debug, optimize 순서를 강조합니다. 체감만으로는 맞춘 듯 보여도 실제 프레임 드랍 원인은 전혀 다른 곳에 있을 수 있기 때문입니다.
- 어떤 화면에서 끊기는지 장면을 먼저 고정한다
- 스크롤인지, 첫 진입인지, 정렬 직후인지 문제 순간을 좁힌다
- Layout Inspector, system trace, Macrobenchmark 같은 도구로 실제 비용 구간을 본다
- 그다음에 stability, key, remember, derivedStateOf를 적용할지 결정한다
특히 리스트 화면은 ‘느리다’는 인상만으로는 원인을 맞히기 어렵습니다. 첫 진입이 느린지, 스크롤 중이 느린지, 정렬 직후만 흔들리는지, 항목 상태 이동이 꼬이는지에 따라 해결책이 서로 달라집니다.
Jetpack Compose 성능 점검 순서
- 이 화면의 느림이 언제 나타나는가
- recomposition 자체가 넓게 번지는가
- skip돼야 할 composable이 unstable 파라미터 때문에 계속 다시 실행되는가
- 리스트 항목에 stable key가 있는가
- composable 안에서 정렬, 필터, 문자열 가공 같은 비싼 계산을 반복하는가
- derivedStateOf나 state hoisting으로 읽기 범위를 줄일 수 있는가
- 그래도 느리면 recomposition 밖의 layout, draw, 이미지, 애니메이션 비용을 본다
이 순서를 지키면 ‘최적화는 많이 했는데 왜 여전히 느리지?’ 같은 상황을 꽤 줄일 수 있습니다. Compose는 마법처럼 빨라지지도, 구조만 바꾸면 자동으로 느려지지도 않습니다. 결국 중요한 것은 무엇이 다시 읽히고, 무엇이 건너뛰어지며, 어디에 실제 비용이 있는지를 차분하게 보는 것입니다.
마무리
Jetpack Compose 성능을 볼 때 recomposition부터 이해해야 하는 이유는, 그래야 stability, key, 리스트 렌더링, remember, derivedStateOf 같은 개별 팁이 하나의 판단 기준으로 연결되기 때문입니다.
- recomposition은 정상 동작이다
- 문제는 범위와 비용, skip 실패다
- stability는 skip 가능성과 연결된다
- 리스트에서는 key가 상태 이동과 성능을 함께 좌우한다
- 비싼 계산은 composable 안에서 반복하지 않는 편이 좋다
- 최적화는 반드시 측정 뒤에 와야 한다
같이 보면 흐름이 더 잘 이어지는 글로는 remember와 rememberSaveable 차이, 안드로이드 UDF는 왜 중요할까, StateFlow와 SharedFlow 차이, Jetpack Compose와 XML 차이를 추천합니다.
공식 기준은 Jetpack Compose Performance, Stability in Compose, Follow best practices, Lazy lists and lazy grids, Practical performance problem solving in Jetpack Compose를 함께 보면 더 선명합니다.

 – 화면 상태는 어디에 두는 게 맞을까")



