
lower bound와 upper bound 차이는 이분 탐색을 공부하다가 꼭 한 번 막히는 지점입니다. 이름은 익숙한데 막상 문제를 풀 때는 어느 쪽을 써야 하는지 헷갈리기 쉽기 때문입니다. 핵심은 단순히 값을 찾는 것이 아니라 조건이 바뀌는 경계 위치를 찾는 것입니다.
이번 글에서는 lower bound와 upper bound를 정의만 외우지 않고, 삽입 위치, 중복 원소 처리, 정답 범위 탐색 문제에서 언제 각각 써야 하는지 코딩테스트 관점으로 자세하게 정리하겠습니다. 이번 보강판에서는 카드와 배열 그림도 함께 넣어 경계가 어떻게 갈리는지 바로 보이게 만들었습니다.
둘 다 결국 무엇을 찾는 걸까
둘 다 정렬된 구간에서 “어디부터 조건이 달라지는가”를 찾는 함수입니다. 즉 특정 값을 찾는 느낌보다, 경계가 시작되는 인덱스를 찾는다는 감각으로 이해하는 편이 훨씬 쉽습니다.
- lower bound: x 이상이 처음 나오는 위치
- upper bound: x 초과가 처음 나오는 위치
이 두 문장을 부등호로만 외우면 금방 헷갈립니다. 대신 배열을 왼쪽 구간과 오른쪽 구간으로 나눈다고 생각하면 훨씬 단순해집니다. lower bound는 왼쪽에 x보다 작은 값만 남기고, upper bound는 왼쪽에 x 이하 값을 남기는 경계입니다.
왜 값 찾기보다 경계 찾기로 봐야 할까
코딩테스트에서 lower bound, upper bound가 자주 나오는 이유는 배열 안에 값이 있는지만 확인하려는 문제가 생각보다 적기 때문입니다. 실제로는 중복 개수 계산, 삽입 위치 결정, 조건을 만족하는 최소 인덱스 찾기처럼 경계 문제가 훨씬 자주 등장합니다.
from bisect import bisect_left, bisect_right
a = [1, 2, 2, 2, 4, 7]
left = bisect_left(a, 2) # 1
right = bisect_right(a, 2) # 4
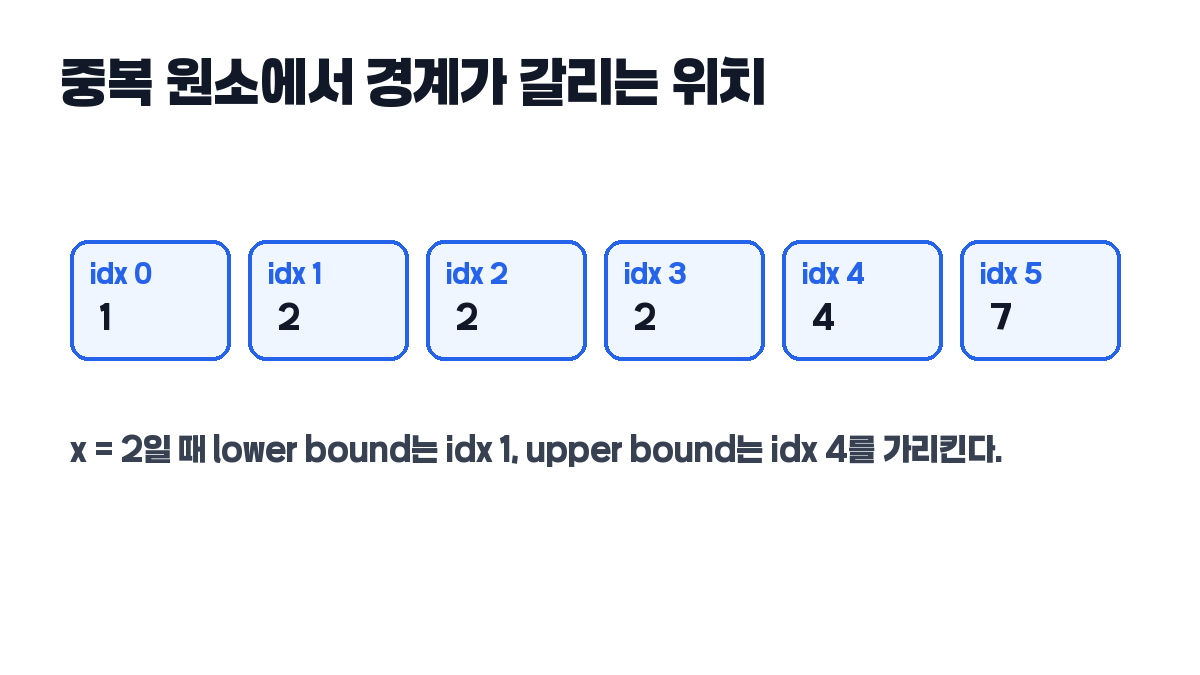
count = right - left # 3이 예시에서 중요한 것은 “2를 찾았다”가 아니라, 2가 시작되는 위치와 끝나는 다음 위치를 각각 구했다는 점입니다. 이 차이를 알면 중복 개수, 존재 여부, 삽입 위치를 한 번에 다룰 수 있습니다.
Python bisect 공식 문서와 C++ lower_bound 설명을 같이 보면, 핵심이 exact match가 아니라 insertion point라는 점이 더 분명해집니다.
문제에서 어떤 신호가 보이면 떠올려야 할까
- 정렬된 배열에서 어떤 값의 개수를 빠르게 세고 싶다
- 조건을 만족하는 최소값 또는 최대값을 찾고 싶다
- 삽입해도 정렬 순서를 유지할 위치를 알고 싶다
- 이분 탐색인데 exact match보다 범위 경계를 묻는다
예를 들어 “이 값 이상이 처음 나오는 위치”, “예산을 이 정도로 잡으면 가능한가”, “조건을 만족하는 가장 작은 답은 무엇인가” 같은 문장은 거의 경계 탐색 문제라고 봐도 됩니다. 이런 문제를 단순 값 탐색으로 풀려고 하면 mid 조건이 자꾸 흔들립니다.
코딩테스트에서 자주 틀리는 이유
- lower bound와 upper bound의 부등호 방향을 헷갈린다
- 정렬되지 않은 배열에 그대로 적용한다
- 중복 개수는 right – left라는 감각이 없다
- 정답 범위 탐색 문제를 단순 값 탐색처럼 푼다
실수 대부분은 구현보다 해석에서 나옵니다. 그래서 부등호를 외우기보다, 경계 왼쪽과 오른쪽에 무엇이 놓이는지를 떠올리는 편이 더 안전합니다. “왼쪽에는 무엇이 남아야 하지?”라고 스스로 묻는 습관이 큰 도움이 됩니다.
문제를 풀다가 mid를 어떻게 움직여야 할지 애매하면, 사실은 값을 찾는 문제가 아니라 경계를 찾는 문제일 가능성이 큽니다. 이 시점에 사고를 바꾸면 구현도 훨씬 단순해집니다.
실전에서 기억하면 좋은 한 줄
lower bound는 조건이 처음 참이 되는 위치, upper bound는 그 조건을 한 단계 더 밀었을 때 처음 참이 되는 위치라고 기억하면 많은 문제가 정리됩니다. 즉 값을 찾는 문제라기보다, 참과 거짓이 갈리는 첫 경계를 찾는 문제입니다.
마무리
lower bound와 upper bound 차이는 결국 값 자체보다 경계를 어디에 두느냐의 차이입니다. lower bound는 x 이상이 시작되는 지점, upper bound는 x 초과가 시작되는 지점이라고 생각하면 훨씬 단순해집니다.
즉 이분 탐색 응용에서 중요한 것은 값을 찾는 기술보다, 조건이 처음 참이 되는 위치를 찾는 사고입니다.




 – 이진 탐색 트리(Binary Search Tree)의 원리, 구조, 예제 코드(C언어, Java, Python), 장단점, 사용 사례 총정리")
