
차분 배열은 누적합을 배운 뒤 자연스럽게 만나게 되는 다음 단계 개념입니다. 많은 사람이 누적합으로 구간 합은 잘 이해했는데, 구간 업데이트 문제가 나오면 다시 한 칸씩 더하는 방식으로 돌아가면서 시간초과를 맞습니다. 바로 이 지점에서 차분 배열이 등장합니다.
이번 글에서는 차분 배열을 단순 공식이 아니라, 구간 전체를 직접 수정하지 않고 변화가 시작되는 지점과 끝나는 지점만 기록하는 방법으로 설명하겠습니다.

누적합만으로는 왜 부족한가
누적합은 이미 만들어진 배열에서 구간 합을 빠르게 구하는 데 강합니다. 하지만 문제 요구가 “이 구간에 5를 더해라”, “이 구간에 -3을 적용해라”처럼 여러 번의 구간 업데이트라면, 매번 모든 칸을 직접 바꾸는 방식은 비효율적입니다.
즉 누적합은 조회 중심 사고이고, 차분 배열은 업데이트 중심 사고라고 보면 됩니다. 둘은 같은 prefix sum 축 위에 있지만 해결하려는 병목이 다릅니다.
차분 배열은 정확히 무엇을 기록할까
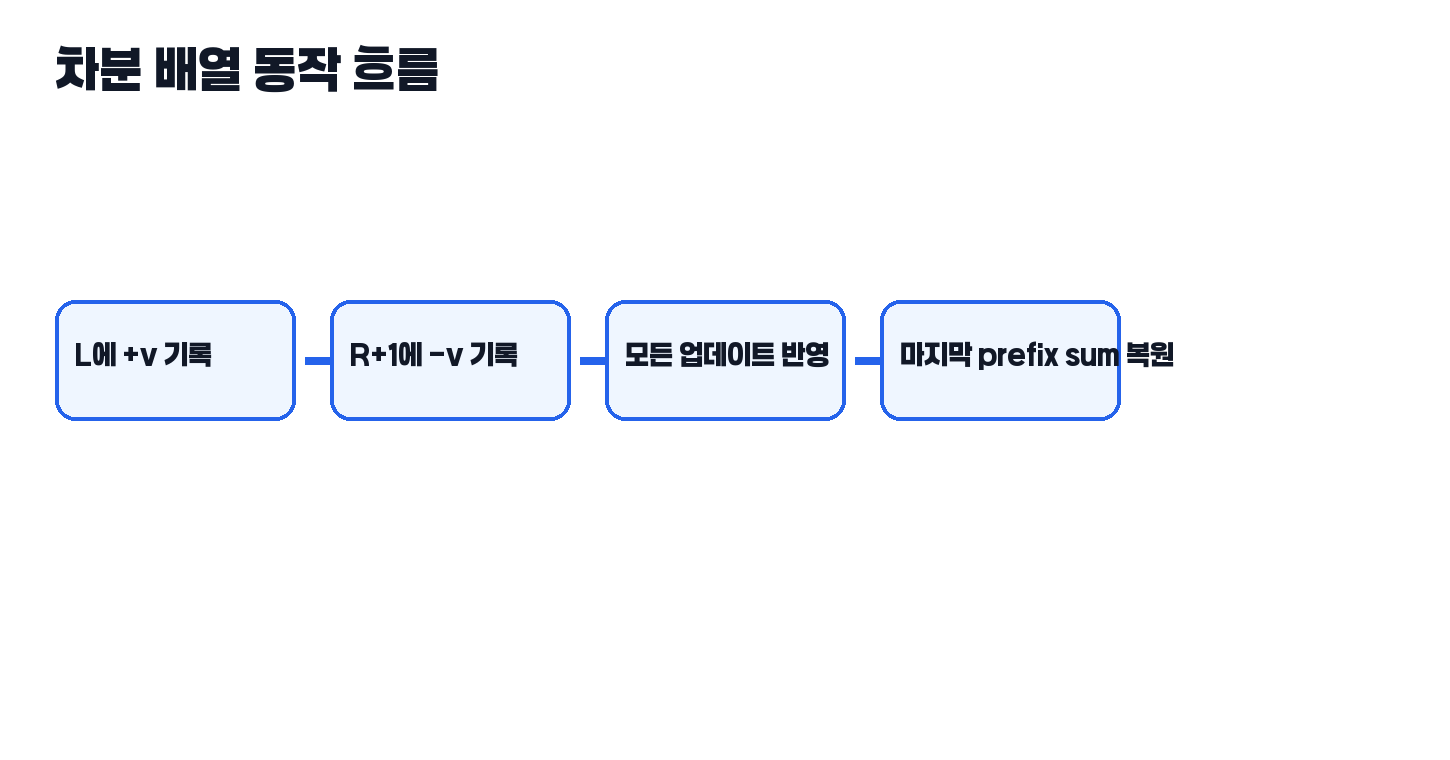
차분 배열은 배열의 각 위치 값을 직접 저장하기보다, 값이 어디서부터 얼마나 변하는지를 기록합니다. 예를 들어 [L, R] 구간에 +v를 적용하고 싶다면, L 위치에서 변화가 시작되므로 +v를 기록하고, R 다음 위치에서는 그 변화가 끝나므로 -v를 기록합니다.
이렇게 해두고 마지막에 한 번 prefix sum을 돌리면, 중간 구간 전체에 +v가 퍼진 것과 같은 효과가 나옵니다. 즉 구간 전체를 다 건드린 것처럼 보이지만 실제 기록은 경계 두 점만 만진 셈입니다.
def range_add(diff, l, r, v):
diff[l] += v
if r + 1 < len(diff):
diff[r + 1] -= v
def build_array(diff):
arr = [0] * len(diff)
cur = 0
for i in range(len(diff)):
cur += diff[i]
arr[i] = cur
return arr입문자가 가장 많이 헷갈리는 부분은 여기서 “왜 끝 다음 칸에 -v를 두지?”입니다. 이유는 변화의 영향이 그 지점에서 끊겨야 하기 때문입니다. L에서 +v를 주면 이후 prefix sum을 따라 계속 누적되므로, R 이후에는 그 효과를 제거해 줘야 합니다.
작은 예시로 보면 훨씬 쉽다
길이 6짜리 배열이 모두 0이라고 해보겠습니다. 여기에 [1, 3] 구간에 +5를 하고, [2, 5] 구간에 +2를 더한다고 가정해보겠습니다.
직접 배열을 수정하면 첫 번째 업데이트 때 1,2,3번 칸을 바꾸고, 두 번째 업데이트 때 2,3,4,5번 칸을 다시 바꿔야 합니다. 하지만 차분 배열에서는 첫 번째 업데이트로 diff[1] += 5, diff[4] -= 5만 기록하고, 두 번째 업데이트로 diff[2] += 2만 기록하면 됩니다. 마지막에 prefix sum을 복원하면 실제 값이 자연스럽게 나옵니다.
즉 차분 배열은 업데이트를 “미루어 적는 메모”에 가깝습니다. 실제 최종 배열은 마지막에 한 번 복원할 때만 완성됩니다.
문제에서 어떤 신호가 보이면 차분 배열일까
- 구간에 같은 값을 여러 번 더하거나 빼야 한다
- 업데이트 횟수가 많아서 직접 수정하면 느리다
- 최종 배열 상태나 한 번의 복원 결과만 필요하다
- 누적합 문제의 다음 단계처럼 보인다
이 신호가 보이면 차분 배열 가능성을 먼저 떠올리는 편이 좋습니다. 특히 “질문마다 즉시 구간 합을 구해야 하는가?” 아니면 “여러 번의 업데이트 후 최종 상태만 보면 되는가?”를 나눠 보면 선택이 훨씬 쉬워집니다.
헷갈리는 포인트
- R 위치가 아니라 R+1 위치에 -v를 두는 이유
- 차분 배열 자체가 최종 배열이 아니라는 점
- 마지막에 prefix sum으로 복원해야 실제 값이 된다는 점
- 인덱스 범위를 넘어갈 때 R+1 처리를 조건으로 막아야 한다는 점
특히 마지막 칸까지 업데이트하는 경우에는 R+1이 배열 밖으로 나갈 수 있으므로 조건 처리가 꼭 필요합니다. 이 경계 실수는 구현은 맞아 보여도 런타임 에러나 한 칸 밀린 오답을 만들기 쉽습니다.
누적합 감각은 누적합 글, 큰 범위를 작은 인덱스로 다루는 발상은 좌표 압축 글과도 연결됩니다.
마무리
차분 배열의 핵심은 구간 전체를 직접 바꾸지 않고, 변화가 시작되는 지점과 끝나는 지점만 기록하는 데 있습니다.
즉 구간 조회가 아니라 구간 업데이트가 병목인 문제라면, 누적합만으로는 부족하고 차분 배열 사고가 필요합니다.



- 정렬 기준 바꾸기")

